
Feed aggregator
Interesting old Monsanto LED's 1972
 | I thought it would interesting to share some of my Dad's old LED's from when he used to work at Monsanto in 1971/1972. [link] [comments] |
Navitas and Cyient partner to accelerate GaN adoption in India
Ascent Solar announces up to $5.5m private placement priced at-the-market under Nasdaq rules
IQE extends multi-year strategic supply agreement with Lumentum
Вітаємо команду dcua Навчально-наукового фізико-технічного інституту

🏆 Студенти КПІ ім. Ігоря Сікорського — переможці національних кіберзмагань National CTF 2025 League of Legends від ГУР МО України!
Tapo or Kasa: Which TP-Link ecosystem best suits ya?

The “smart home” market segment is, I’ve deduced after many years of observing it and, in a notable number of “guinea pig” cases, personally participating in it (with no shortage of scars to show for my experiments and experiences), tough for suppliers to enter and particularly remain active for any reasonable amount of time. I generally “bin” such companies into one of three “buckets”, ordered as follows in increasing “body counts”:
- Those that end up succeeding long-term as standalone entities (case study: Wyze)
- Those who end up getting acquired by larger entities (case studies: Blink, Eero, and Ring, all by Amazon, and Nest, by Google)
- And the much larger list of those who end up fading away (one recent example: Neato Robotics’ robovacs), a demise often predated by an interim transition of formerly-free associated services to paid (one-time or, more commonly, subscription-based) successors as a last-gasp revenue-boosting move, and a strategy that typically fails due to customers instead bailing and switching to competitors.
There’s one other category that also bears mentioning, which I’ll be highlighting today. It involves companies that remain relevant long-term by periodically culling portions of the entireties of product lines within the overall corporate portfolio when they become fiscally unpalatable to maintain. A mid-2020 writeup from yours truly, as an example, showcased a case study of each; Netgear stopped updating dozens of router models’ firmware, leaving them vulnerable to future compromise in favor of instead compelling customers to replace the devices with newer models (four-plus years later, I highlighted a conceptually similar example from Western Digital), and Best Buy dumped its Connect smart home device line in its entirety.
A Belkin debacle
Today’s “wall of shame” entry is Belkin. Founded more than 40 years ago, the company today remains a leading consumer electronics brand; just in the past month or so, I’ve bought some multi-port USB chargers, a couple of MagSafe Charging Docks, several RockStar USB-C and Lightning charging-plus-headphone adapters, and a couple of USB-C cables from them. Their Wemo smart plugs, on the other hand…for a long time, truth be told, I was a “frequent flyer” user and fan of ‘em. See, for example, these teardowns and hands-on evaluation articles:
- WeMo Switch is highly integrated (November 2015)
- Home automation control on the go (March 2016)
- A Wi-Fi smart plug for home automation (August 2018)
A few years ago, however, my Wemo love affair started to fade. Researchers had uncovered a buffer overflow vulnerability in older units, widely reported in May 2023, that allowed for remote control and broader hacking. But Belkin decided to not bother fixing the flaw, because affected devices were “at the end of their life and, as a result, the vulnerability will not be addressed” (whether it could have even been fixed with just a firmware update, with Belkin’s decline to do so therefore just a fundamental business decision, or reflected a fundamental hardware flaw necessitating a much more costly replacement of and/or refunds for affected devices, was never made clear to the best of my knowledge).
Two-plus years later, and earlier this summer, Belkin effectively pulled the plug on the near- entirety of the Wemo product line by announcing the pending sever of devices’ tethers not only to the Wemo mobile app and associated Belkin server-side account and devices’ management facilities, in a very Insteon-reminiscent move, but also in the process the “cloud” link to Amazon’s Alexa partner services. Ironically, the only remaining viable members of the Wemo product line after January 31, 2026 will be a few newer products that are alternatively controllable via the Thread protocol. As I aptly noted within my 2024 CES coverage:
Consider that the fundamental premise of Matter and Thread was to unite the now-fragmented smart home device ecosystem exemplified by, for example, the various Belkin Wemo devices currently residing in my abode. If you’re an up-and-coming startup in the space, you love industry standards, because they lower your market-entry barriers versus larger, more established competitors. Conversely, if you’re one of those larger, more established suppliers, you love barriers to entry for your competitors. Therefore the lukewarm-at-best (and more frequently, nonexistent or flat-out broken) embrace of Matter and Thread by legacy smart home technology and product suppliers.
Enter TP-LinkClearly, it was time for me to look for a successor smart plug product line supplier and device series. Amazon was the first name that came to mind, but although its branded Smart Plug is highly rated, it’s only controllable via Alexa:

I was looking for an ecosystem that, like Wemo, could be broadly managed, not only by the hardware supplier’s own app and cloud services but also by other smart home standards such as the aforementioned Amazon (Alexa), along with Apple (HomeKit and Siri), Google (Home and Assistant, now transitioning to Gemini), Samsung (SmartThings), and ideally even open-source and otherwise vendor-agnostic services such as IFTTT and Matter-and-Thread.
I also had a specific hardware requirement that still needed to be addressed. The fundamental reason why we’d brought smart plugs into the home in the first place was so that we could remotely turn off the coffee maker in the kitchen if we later realized that we’d forgotten to do so prior to leaving the home; my wife’s bathroom-located curling iron later provided another remote-power-off opportunity. Clearly, standard smart plugs designed for low-wattage lamps and such wouldn’t suffice; we needed high-current-capable switching devices. And this requirement led to the first of several initially confusing misdirections with my ultimately selected supplier (motivated by rave reviews at The Wirecutter and elsewhere), TP-Link.

I admittedly hadn’t remembered until I did research prior to writing this piece that I’d actually already dissected an early TP-Link smart plug, the HS100, back in early 2017. That I’d stuck with Belkin’s Wemo product line for years afterward, admittedly coupled with my increasingly geriatric brain cells, likely explains the memory misfire. That very same device, along with its energy-monitoring HS110 sibling, had launched the company’s Kasa smart home device brand two years earlier, although looking back at the photos I took at the time I did my teardown, I can’t find a “Kasa” moniker anywhere on the device or its packaging, so…
My initial research indicated that the TP-Link Kasa HS103 follow-on, introduced a few years later and still available for purchase, would, along with the related HS105 be a good tryout candidate:

The two devices supposedly differed in their (resistive load) current-carrying capacity: 10 A max for the HS103 and 15 A for the HS105. I went looking for the latter, specifically for use with the aforementioned coffee maker and curling iron. But all I could find for sale was the former. It turns out that TP-Link subsequently redesigned and correspondingly up-spec’d the HS103 to also be 15A-capable, effectively obsoleting the HS105 in the process.
Smooth sailing, at least at firstAnd I’m happy to say that the HS103 ended up being both a breeze to set up and (so far, at least) 100% reliable in operation. Like the HS100 predecessor, along with other conceptually similar devices I’ve used in the past, you first connect to an ad-hoc Wi-Fi connection broadcast by the smart plug, which you use to send it your wireless LAN credentials via the mobile app. Then, once the smart plug reboots and your mobile device also reconnects to that same wireless LAN, they can see and communicate with each other via the Kasa app:
















And then, after one-time initially installing Kasa’s Alexa skill and setting up my first smart plug in it, subsequent devices added via the Kasa app were then automatically added in Alexa, too:















The latest published version of the Wirecutter’s coverage had actually recommended a newer, slightly smaller (but still 15A-capable) TP-Link smart plug, the EP10, so I decided to try it next:

Unfortunately, although the setup process was the same, the end result wasn’t:

This same unsuccessful outcome occurred with multiple devices from the first two EP10 four-pack sets I tried, which, like their HS103 forebears, I’d sourced from Amazon. Remembering from past experiences that glitches like this sometimes happen when a smartphone—which has two possible network connections, Wi-Fi and cellular—is used for setup purposes, I first disabled cellular data services on my Google Pixel 7, then tried a Wi-Fi-only iPad tablet instead. No dice.
I wondered if these particular smart plugs, which, like their seemingly more reliable HS103 precursors, are 2.4 GHz Wi-Fi-only, were somehow getting confused by one or more of the several relatively unique quirks of my Google Nest Wifi wireless network:
- The 2.4 GHz and 5 GHz Wi-Fi SSIDs broadcast by any node are the same name, and
- Being a mesh configuration, all nodes (both stronger-signal nearby and weaker, more distant, to which clients sometimes connect instead) also have the exact same SSID
Regardless, I couldn’t get them to work no matter what I tried, so I sent them back for a refund…
Location awareness…only to then have the bright idea that it’d be cool to take both an HS103 and an EP10 apart and see if there was any hardware deviation that might explain the functional discrepancy. So, I picked up another EP10 combo, this one a two-pack. And on a “third time’s the charm” hunch (and/or maybe just fueled by stubbornness), I tried setting one of them up again. Of course, it worked just fine this time






This time, I decided to try a new use case: controlling a table lamp in our dining room that automatically turned on at dusk and turned off again the next morning. We’d historically used an archaic mechanical timer for lamp power control, an approach not only noisy in operation but which also needed to be re-set after each premises electricity outage, since the timer didn’t embed a rechargeable battery to act as a temporary backup power source and keep time:




The mechanical timer was also clueless about the varying sunrise and sunset times across the year, not to mention the twice-yearly daylight saving time transitions. Its smart plug successor, which knows where it is and what day and time it is (whenever it’s powered up and network-connected, of course), has no such limitations:




Spec changes…inconsistent setup outcomes…there’s one more bit of oddity to share in closing. As this video details:
“Kasa” was TP-Link’s original smart home device brand, predominantly marketed and sold in North America. The company, for reasons that remain unclear to me and others, subsequently, in parallel, rolled out another product line branded as “Tapo” across the rest of the world. Even today, if you revisit the “smart plugs” product page on TP-Link’s website, whose link I first shared earlier in this writeup, you’ll see a mix of Kasa- and Tapo-branded products. The same goes for wall switches, light bulbs, cameras, and other TP-Link smart home devices. And historically, you needed to have both mobile apps installed to fully control a mixed-brand setup in your home.
Fortunately, TP-Link has made some notable improvements of late, from which I’m reading between the lines and deducing that a full transition to Tapo is the ultimate intended outcome. As I tested and confirmed for myself just a couple of days ago, it’s now possible to manage both legacy Kasa and newer Tapo devices using the same Tapo app; they also leverage a common TP-Link user account:









They all remain visible to Alexa, too, and there’s a separate Tapo skill that can also be set up:




along with, as with Kasa, support for other services:


To wit, driven by curiosity as to whether device functional deviations are being fueled by (in various cases) hardware differences, firmware-only tweaks or combinations of the two, I’ve taken advantage of a 30%-off Black Friday (week) promotion to also pick up a variety of other TP-Link smart plugs from Amazon’s Resale (formerly Warehouse) area, for both functional and teardown analysis in the coming months:
- Kasa EP25 (added Apple HomeKit support, also with energy monitoring)
- Tapo P105 (seeming Tapo equivalent to the Kasa EP10)
- Tapo P110M (Matter compatible, also with energy monitoring)
- Tapo P115 (energy monitoring)
- Tapo P125 (added Apple HomeKit support)
Some of these devices look identical to others, at least from the outside, while in other cases dimensions and button-and-LED locations differ product-to-product. But for us engineers, it’s what’s on the inside that counts. Stand by for further writeups in this series throughout 2026. And until then, let me know your thoughts on what I’ve covered so far in the comments!
—Brian Dipert is the Principal at Sierra Media and a former technical editor at EDN Magazine, where he still regularly contributes as a freelancer.
Related Content
- How smart plugs can make your life easier and safer
- Teardown: Smart plug adds energy consumption monitoring
- Teardown: A Wi-Fi smart plug for home automation
- Teardown: Smart switch provides Bluetooth power control
The post Tapo or Kasa: Which TP-Link ecosystem best suits ya? appeared first on EDN.
The Era of Engineering Physical AI
Courtesy: Synopsys
Despite algorithmic wizardry and unprecedented scale, the engineering behind AI has been relatively straightforward. More data. More processing.
But that’s changing.
With an explosion of investment and innovation in robots, drones, and autonomous vehicles, “physical AI” is making the leap from science fiction to everyday reality. And the engineering behind this leap is anything but straightforward.
No longer confined within the orderly, climate-controlled walls of data centers, physical AI must be engineered — from silicon to software to system — to navigate countless new variables.
Sudden weather shifts. A cacophony of signals and noise. And the ever-changing patterns of human behavior.
Bringing physical AI into these dynamic settings demands far more than sophisticated algorithms. It requires the intricate fusion of advanced electronics, sensors, and the principles of multiphysics — all working together to help intelligent machines perceive, interpret, and respond to the complexities of the physical world.
The next frontier for AI: physics
We have taught AI our languages and imparted it with our collective knowledge. We’ve trained it to understand our desires and respond to our requests.
But the physical world presents a host of new challenges. If you ask AI about potholes, it will tell you how they’re formed and how to repair them. But what happens when AI encounters a large pothole in foggy, low-light conditions during the middle of rush hour?
Our environment is highly dynamic. But the one, unbending constant? Physics. And that’s why physics-based simulation is foundational to the development of physical AI.
For AI to function effectively in the real world, it needs finely tuned sensors — such as cameras, radar, and LiDAR — that deliver correlated environmental data, allowing physical AI systems to accurately perceive and interpret their surroundings.
Physics-based simulation allows engineers to design, test, and optimize these sensors — and the systems they support — digitally, which is significantly less expensive than physical prototypes. Answers to critical “what-if” questions can be attained, such as how varying weather conditions or material reflectivity impact performance. Through simulation, engineers can gather comprehensive and predictive insights on how their systems will respond to countless operating scenarios.
Equally important to being able to “see” our world is how well physical AI is trained to “think.” In many cases, we lack the vast, diverse datasets required to properly train nascent physical AI systems on the variables they will encounter. The rapid emergence of synthetic data increasingly helps innovators bridge the gap, but accuracy has been a concern.
Exciting progress has been made on this front. Powerful development platforms — such as NVIDIA’s Omniverse — can be used to create robust virtual worlds. When integrated with precise simulation tools, these platforms enable developers to import high-fidelity physics into their scenario to generate reliable synthetic data.
Re-engineering engineering from silicon to systems
Design and engineering methodologies have traditionally been siloed and linear, with a set of hardware and software components being developed or purchased separately prior to assembly, test, and production.
These methodologies are no longer viable — for physical AI or other silicon-powered, software-defined products.
Consider a drone. To fly autonomously, avoid other objects, and respond to operator inputs, many things must work in concert. Advanced software, mechanical parts, sensors, custom silicon, and much more.
Achieving this level of precision — within imprecise environments — can’t be achieved with traditional methodologies. Nor can it be delivered within the timelines the market now demands.
Digitally enhanced products must be designed and developed as highly complex, multi-domain systems. Electrical engineers, mechanical engineers, software developers, and others must work in lockstep from concept to final product. And their work must accelerate to meet shrinking development cycles.
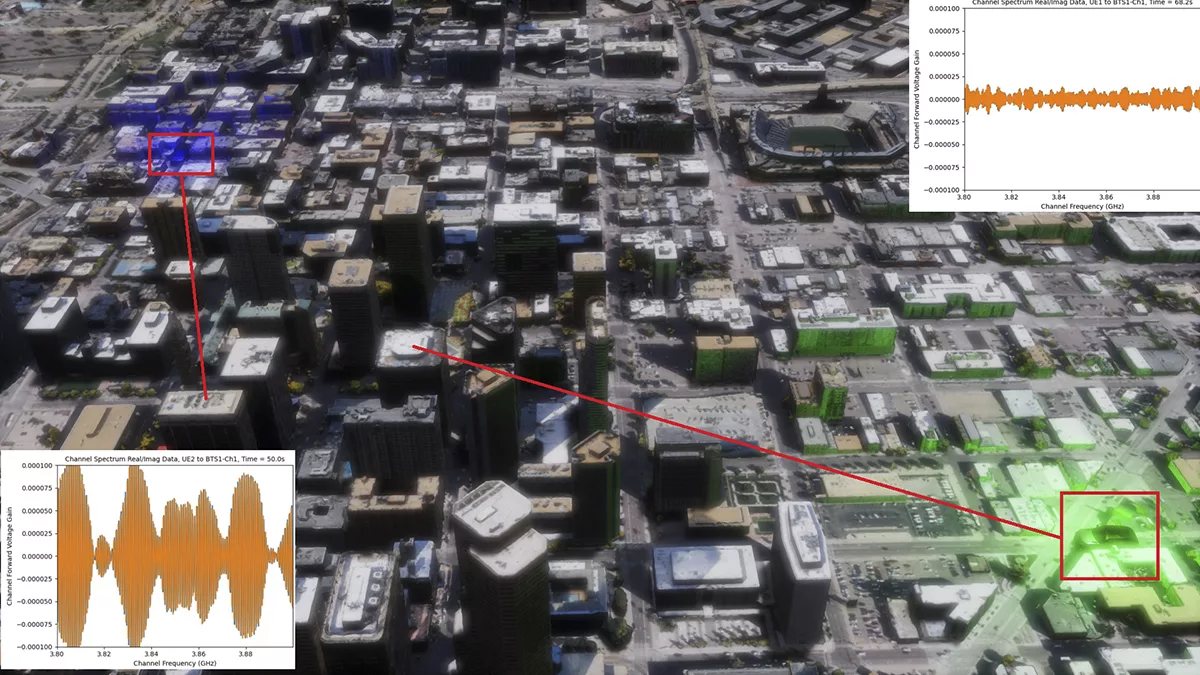
 Ansys electromagnetic simulation software within a rendering of downtown San Jose in NVIDIA Omniverse with 5 cm resolution
Ansys electromagnetic simulation software within a rendering of downtown San Jose in NVIDIA Omniverse with 5 cm resolution
The complexity of today’s intelligent systems demands solutions with a deeper integration of electronics and physics. Engineering solution providers are moving fast to meet this need.
Conclusion
Physical AI is pushing engineering into uncharted territory—far beyond the comfort of controlled data centers and into the unpredictable, physics-governed world we live in. Delivering machines that can truly see, think, and act in real time requires more than clever algorithms; it demands a new model of engineering rooted in high-fidelity simulation, cross-domain collaboration, and deeply integrated electronics and software.
As sensors, computing, and simulation technologies converge, engineers are gaining the tools to design intelligent systems that can anticipate challenges, adapt to dynamic conditions, and operate safely in complex environments. The leap from digital AI to physical AI is not just an evolution—it’s a reinvention of how we build technology itself. And with the accelerating progress in multiphysics modeling, synthetic data generation, and unified development platforms, the industry is rapidly assembling the foundation for the next era of autonomous machines.
Physical AI is no longer a distant vision. It is becoming real, and the engineering innovations taking shape today will define how seamlessly—and how safely—intelligent systems fit into the world of tomorrow.
The post The Era of Engineering Physical AI appeared first on ELE Times.
SFO Technologies plans to invest Rs. 2,270 crore for a PCB manufacturing plant in Tamil Nadu
SFO technologies plans to set up a plant in Theni, Tamil Nadu with an investment of Rs. 2,270 crore for manufacturing printed circuit boards (PCBs) and other components for the electronics industry, a senior executive at the Kochi-based company said.
An unnamed senior level source from the company revealed that the the flagship company of the NeST Group, is expected to sign a memorandum of understanding on the project with the Tamil Nadu government at the TN Rising Conclave in Madurai on Sunday.
PCBs are used in nearly all modern consumer electronic devices and accessories, including phones, tablets, smartwatches, wireless chargers, and power supplies. At the proposed plant in Theni, the company is also considering manufacturing components like composites, connectors, relays and optical transceivers.
SFO has expressed a demand for 60 acre of land piece to begin manufacturing facilities at the unit in the next two years, scaling it to its full capacity in the next six years
The source said the company is considering Theni for the project also because of its wind energy potential. The plant could possibly meet its power demand through renewable sources of energy, he said.
The company’s plan is to start with PCBs in Theni, the executive said. “As part of our proposal, we have also requested for some land towards Krishnagiri, for a plant that will be intended for connectors,” he said.
The post SFO Technologies plans to invest Rs. 2,270 crore for a PCB manufacturing plant in Tamil Nadu appeared first on ELE Times.
Silicon MOS quantum dot spin qubits: Roads to upscaling

Using quantum states for processing information has the potential to swiftly address complex problems that are beyond the reach of classical computers. Over the past decades, tremendous progress has been made in developing the critical building blocks of the underlying quantum computing technology.
In its quest to develop useful quantum computers, the quantum community focuses on two basic pillars: developing ‘better’ qubits and enabling ‘more’ qubits. Both need to be simultaneously addressed to obtain useful quantum computing technology.
The main metrics for quantifying ‘better’ qubits are their long coherence time—reflecting their ability to store quantum information for a sufficient period, as a quantum memory—and the high qubit control fidelity, which is linked to the ‘errors’ in controlling the qubits: sufficiently low control errors are a prerequisite for successfully performing a quantum error correction protocol.
The demand for ‘more’ qubits is driven by practical quantum computation algorithms, which require the number of (interconnected) physical qubits to be in the millions, and even beyond. Similarly, quantum error correction protocols only work when the errors are sufficiently low: otherwise, the error correction mechanism actually ‘increases’ error, and the protocols diverge.
Of the various quantum computing platforms that are being investigated, one stands out: silicon (Si) quantum dot spin qubit-based architectures for quantum processors, the ‘heart’ of a future quantum computer. In these architectures, nanoscale electrodes define quantum dot structures that trap a single electron (or hole), its spin states encoding the qubit.
Si spin qubits with long coherence times and high-fidelity quantum gate operations have been repeatedly demonstrated in lab environments and are therefore a well-established technology with realistic prospects. In addition, the underlying technology is intimately linked with CMOS manufacturing technologies, offering the possibility of wafer-scale uniformity and yield, an important stepping stone toward realizing ‘more’ qubits.
A sub-class of Si spin qubits uses metal-oxide-semiconductor (MOS) quantum dots to confine the electrons, a structure that closely resembles a traditional MOS transistor. The small size of the Si MOS quantum dot structure (~100 nm) offers an additional advantage to upscaling.
Low qubit charge noise: A critical requirement to scale up
In the race toward upscaling, Si spin qubit technology can potentially leverage advanced 300-mm CMOS equipment and processes that are known for offering a high yield, high uniformity, high accuracy, high reproducibility and high-volume manufacturing—the result of more than 50 years of down selection and optimization. However, the processes developed for CMOS may not be the most suitable for fabricating Si spin quantum dot structures.
Si spin qubits are extremely sensitive to noise coming from their environment. Charge noise, arising from the quantum dot gate stack and the direct qubit environment, is one of the most widely identified causes of reduced fidelity and coherence. Two-qubit ‘hero’ devices with low charge noise have been repeatedly demonstrated in the lab using academic-style techniques such as ‘lift off’ to pattern the quantum dot gate structures.
This technique is ‘gentle’ enough to preserve a good quality Si/SiO2 interface near the quantum dot qubits. But this well-controlled fabrication technique cannot offer the required large-scale uniformity needed for large-scale systems with millions of qubits.
On the other hand, industrial fabrication techniques like subtractive etch in plasma chambers filled with charged ions or lithography-based patterning based on such etching processes easily degrade the device and interface quality, enhancing the charge noise of Si/SiO2-based quantum dot structures.
First steps in the lab-to-fab transition: Low-charge noise and high-fidelity qubit operations achieved on an optimized 300–mm CMOS platform
Imec’s journey toward upscaling Si spin qubit devices began about seven years ago, with the aim of developing a customized 300-mm platform for Si quantum dot structures. Seminal work led to a publication in npj Quantum Information in 2024, highlighting the maturity of imec’s 300-mm fab-based qubit processes toward large-scale quantum computers.
Through careful optimization and engineering of the Si/SiO2-based MOS gate stack with a poly-Si gate, charge noise levels of 0.6 µeV/ÖHz at 1Hz were demonstrated, the lowest values achieved on a fab-compatible platform at the time of publication. The values could be demonstrated repeatedly and reproducibly.

Figure 1 These Si MOS quantum dot structures are fabricated using imec’s optimized 300-mm fab-compatible integration flow. Source: imec
More recently, in partnership with the quantum computing company Diraq, the potential of imec’s 300mm platform was further validated. The collaborative work, published in Nature, showed high-fidelity control of all elementary qubit operations in imec’s Si quantum dot spin qubit devices. Fidelities above 99.9% were reproducibly achieved for qubit preparation and measurement operations.
Fidelity values systematically exceeding 99% were shown for one- and two-qubit gate operations, which are the operations performed on the qubits to control their state and entangle them. These values are not arbitrarily chosen. In fact, whether quantum error correction ‘converges’ (net error reduction) or ‘diverges’ (the net error introduced by the quantum error correction machinery increases) is crucially dependent on a so-called threshold value of about 99%. Hence, fidelity values over 99% are required for large scale quantum computers to work.

Figure 2 Schematic of a two-qubit Diraq device on a 300-mm wafer shows the full-wafer, single-die, and single-device level. Source: imec
Charge noise was also measured to be very low, in line with the previous results from the npj Quantum Information paper. Gate set tomography (GST) measurements shed light on the residual errors; the low charge noise values, the coupling between the qubit, and the few remaining residual nuclear-spin-carrying Si isotopes (29Si) turned out to be the main factor in limiting the fidelity for these devices. These insights show that even higher fidelities can be achieved through further isotopic enrichment of the Si layer with 28Si.
In the above studies, the 300-mm processes were optimized for spin qubit devices in an overlapping gate device architecture. Following this scheme, three layers of gates are patterned in an overlapping and more or less self-aligned configuration to isolate and confine an electron. This multilayer gate architecture, extensively studied and optimized within the quantum community, offers a useful vehicle to study individual qubit metrics and small-scale arrays.

Figure 3 Illustration of a triple quantum dot design uses overlapping gates; electrons are shown as yellow dots. The gates reside in three different layers: GL1, GL2, and GL3, as presented at IEDM 2025. Source: imec
The next step in upscaling: Using EUV for gate patterning to provide higher yield, process control, and overlay accuracy
Thus far, imec used a wafer-scale, 300-mm e-beam writer to print the three gate layers that are central to the overlapping gate architecture. Although this 300-mm-compatible technique facilitates greater design flexibility and small pitches between quantum dots, it comes with a downside: its slow writing time does not allow printing full 300-mm wafers in a reasonable process time.
At IEDM 2025, imec for the first time demonstrated the use of single-print 0.33 NA EUV lithography to pattern the three gate layers of the overlapping gate architecture. EUV lithography has by now become the mainstay for industrial CMOS fabrication of advanced (classical) technology nodes; imec’s work demonstrates that it can be equally used to define and fabricate good quantum dot qubits. This means a significant leap forward in upscaling Si spin qubit technology.
Full 300-mm wafers can now be printed with high yield and process control—thereby fully exploiting the reproducibility of the high-quality qubits shown in previous works. EUV lithography brings an additional advantage: it allows the different gates to be printed with higher overlay accuracy than with the e-beam tools. That benefits the quality of the qubits and allows being more aggressive in the dot-to-dot pitches.

Figure 4 TEM and SEM images, after patterning the gate layers with EUV, highlight critical dimensions, as presented at IEDM 2025. Source: imec
The imec researchers demonstrated robust reproducibility, full-wafer room temperature functionality, and good quantum dot and qubit metrics at 10 mK. Charge noise values were also comparable to measurements on similar ‘ebeam-lithography’ devices.
Inflection point: Moving to scalable quantum dot arrays to address the wiring bottleneck
The overlapping gate architecture, however, is not scalable to the large quantum dot arrays that will be needed to build a quantum processor. The main bottleneck is connectivity: each qubit needs individual control and readout wiring, making the interconnect requirements very different from those of classical electronic circuits. In the case of overlapping gates, wiring fanout is provided by the different gate layers, and this imposes serious limitations on the number of qubits the system can have.
Several years ago, a research group at HRL Laboratories in the United States came up with a more scalable approach to gate integration: the single-layer gate device architecture. In this architecture, the gates that are needed to isolate the electrons—the so-called barrier and plunger gates—are fabricated in one and the same layer, more closely resembling how classical CMOS transistors are built and interconnected using a multilayer back end of line (BEOL).
Today, research groups worldwide are investigating how large quantum dot arrays can be implemented in such a single-layer gate architecture, while ensuring that each qubit can be accessed by external circuits. At first sight, the most obvious way is a 2D lattice, similar to integrating large memory arrays in classic CMOS systems.
But eventually, this approach will hit a wiring scaling wall as well. The NxN quantum dot array requires a large number of BEOL layers for interconnecting the quantum dots. Additionally, ensuring good access for reading and controlling qubits that are farther away from the peripheral charge sensors becomes challenging.
A trilinear quantum dot architecture: An imec approach
At IEDM 2021, imec therefore proposed an alternative, smart way of interconnecting neighboring silicon qubits: the bilinear array. The design is based on topologically mapping a 2D square lattice to form a bilinear design, where alternating rows of the lattice are shifted into two rows (or 1D arrays).
While the odd rows of the 2D lattice are placed into an upper 1D array, the even rows are moved to a lower 1D array. In this configuration, all qubits remain addressable while maintaining the target connectivity of four in the equivalent 2D square lattice array. These arrays are conceptually scalable as they can further grow in one dimension, along the rows.
Recently, the imec researchers expanded this idea toward a trilinear quantum dot device architecture that is compatible with the single-layer gate integration approach. With this trilinear architecture, a third linear array of (empty) quantum dots is introduced between the upper and lower rows. This extra layer of quantum dots now serves as a shuttling array, enabling qubit connectivity via the principle of qubit shuttling.

Figure 5 View the concept of mapping a 2D lattice onto a bilinear design and expanding that design to a trilinear architecture. The image illustrates the principle of qubit shuttling for the interaction between qubits 6 and 12. Source: imec

Figure 6 Top view of a 3×5 trilinear single gate array is shown with plunger (P) and barrier (B) gates placed in a single layer, as presented at IEDM 2025. Source: imec
The video below explains how that works. In the trilinear array, single and some of the two-qubit interactions can happen directly between nearest neighbors, the same way as in the bilinear architecture. For others, two-qubit interactions can be performed through the ‘shuttle bus’ that is composed of empty quantum dots. Take a non-nearest neighbor interaction between two qubits as an example.
The video shows schematics, conceptual operation, and manufacturing of trilinear quantum dot architecture. Source: imec
The first qubit is moved to the middle array, shuttled along this array to the desired site to perform the two-qubit operation with a second, target qubit, and shuttled back. These ‘all-to-all’ qubit interactions were not possible using the bilinear approach. Note that these interactions can only be reliably performed with high-fidelity quantum operations to ensure that no information is lost during the shuttling operation.
But how can this trilinear quantum dot architecture address the wiring bottleneck? The reason is the simplified BEOL structure: only two metal layers are needed to interconnect all the quantum dots. For the upper and lower 1D arrays, barrier and plunger gates can connect to one and the same metal layer (M1); the middle ‘shuttle’ array can partly connect to the same M1 layer, partly to a second metal layer (M2). Alongside the linear array, charge sensors can be integrated to measure the state of the quantum dots for qubit readout.
The architecture is also scalable in terms of number of qubits, as the array can further grow along the rows. If that approach at some point hits a scaling wall, it can potentially be expanded to four, five or even more linear arrays, ‘simply’ by adding more BEOL layers.
Using EUV lithography to process the trilinear quantum dot architecture: A world first
At IEDM 2025, imec showed the feasibility of using EUV lithography for patterning the critical layers of this trilinear quantum dot architecture. Single-print 0.33 NA EUV lithography was used to print the single-layer gate, the gate contacts, and the two BEOL metal layers and vias.

Figure 7 Single-layer gate trilinear array is shown after EUV lithography and gate etch with TEM cross sections in X and Y directions, as presented at IEDM 2025. Source: imec
One of the main challenges was achieving a very tight pitch across all the different layers without pitch relaxation. The gate layer was patterned with a bidirectional gate pitch of 40 nm. It was the first time ever that such an ‘unconventional’ gate structure was printed using EUV lithography, since EUV lithography for classical CMOS applications mostly focuses on unidirectional patterns. Next, 22-nm contact holes were printed with <2.5 nm (mean + 3 sigma) contact-to-gate overlay in both directions. The two metal layers M1 and M2 were patterned with metal pitch in the order of 50 nm.






Figure 8 From top to bottom, see the trilinear array (a-c) after M1 and (d-f) after M2 patterning, as presented at IEDM 2025. Source: imec
In the race for upscaling, the use of EUV lithography allows full 300-mm wafers to be processed with high yield, uniformity, and overlay accuracy between the critical structures. First measurements already revealed a room temperature yield of 90% across the wafer, and BEOL functionality was confirmed using dedicated test structures.
The use of single-patterning EUV lithography additionally contributes to cost reduction by avoiding complex multi-patterning schemes and to the overall resolution of the printed features. Moreover, the complexity and asymmetry of the 2D structure cannot be achieved with double patterning techniques.
The outlook: Upscaling and further learnings
In pursuit of enabling quantum systems with increasingly more qubits, imec made major strides: first, reproducibly achieving high-fidelity unit cells on two-qubit devices; second, transitioning from ebeam to EUV lithography for patterning critical layers; and third, moving from overlapping gate architectures to a single-layer gate configuration.
Adding EUV to imec’s 300-mm fab-compatible Si spin qubit platform will enable printing high-quality quantum dot structures across a full 300-mm wafer with high yield, uniformity, and alignment accuracy.
The trilinear quantum dot architecture, compliant with the single-layer gate approach, will allow upscaling the number of qubits by addressing the wiring bottleneck. Currently, work is ongoing to electrically characterize the trilinear array, and to study the impact of both the single-layer gate approach and the use of EUV lithography on the qubit fidelities.
The trilinear quantum dot architecture is a stepping stone toward truly large-scale quantum processors based on silicon quantum dot qubits. It may eventually not be the most optimal architecture for quantum operations involving millions of qubits, and clear bottlenecks remain.
But it’s a step in the learning process toward scalability and allows de-risking the technology around it. It will enhance our understanding of large-scale qubit operations, qubit shuttling, and BEOL integration. And it will allow exploring the expandability of the architecture toward a larger number of arrays.
In parallel, imec will continue working on the overlapping gate structure which can offer very high qubit fidelities. These high-quality qubits can be used as a probe to further study and optimize the qubit’s gate stack, understand the limiting noise mechanisms, tweak and optimize the control modules, and develop the measurement capability for larger scale systems in a systematic, step-by-step approach—leveraging the process flexibility offered by imec’s 300-mm infrastructure.
It’s a viable research vehicle in the quest for better qubits, providing learnings much faster than any large-scale quantum dot architecture. It can help increase our fundamental knowledge of two-qubit systems, an area in which there is still much to learn.
Sofie Beyne, project manager for quantum computing at imec, started her career at Intel, working as an R&D reliability engineer on advanced nodes in the Logic Technology Development department. She rejoined imec in 2023 to focus on bilateral projects around spin qubits.
Clement Godfrin, device engineer at imec, specializes in the dynamics of single nuclear high spin, also called qudit, either to implement quantum algorithm proof of principle on single nuclear spin of a molecular magnet system, or quantum error correction protocol on single donor nuclear spin.
Stefan Kubicek, integration engineer at imec, has been involved in CMOS front-end integration development from 130-nm CMOS node to 14-nm FinFET node. He joined imec in 1998, and since 2016, he has been working on the integration of spin qubits.
Kristiaan De Ggreve, imec fellow and program director for quantum computing at imec, is also Proximus Chair at Quantum Science and Technology and professor of electrical engineering at KU Leuven. He moved to imec in 2019 from Harvard University, where he was a fellow in the physics department and where he retains a visiting position.
Related Content
- Quantum Computers Explained
- The Basics Of Quantum Computing
- Race to Find the Next Nvidia in Quantum Computing
- Silicon Spin Qubits: Scaling Toward the Million-Qubit Era
- Impact of Quantum Computing on Next-Generation Chip Development
The post Silicon MOS quantum dot spin qubits: Roads to upscaling appeared first on EDN.
Gartner Forecasts Having 116 Million EVs on the Road in 2026
Gartner, Inc., a business and technology insights company predicts to have 116 million electric vehicles (EVs), including cars, buses, vans and heavy trucks on the road in 2026.
According to the research by the company, battery electric vehicles (BEVs) are forecast to continue to account for well over half of EV installed base, but there is an increasing proportion of customers choosing PHEVs (see Table 1).
Table 1. Electric Vehicle Installed Base by Vehicle Type, Worldwide, 2025-2026 (Single Units)
|
2025 Installed Base |
2026 Installed Base |
|
|
Battery Electric Vehicles (BEV) |
59,480,370 | 76,344,452 |
| Plug-in Hybrid Electric Vehicles (PHEV) | 30,074,582 | 39,835,111 |
| Total | 89,554,951 | 116,179,563 |
Source: Gartner (December 2025)
Expert Take:
“Despite the U.S. government introducing tariffs on vehicle imports and many governments removing the subsidies and incentives for purchasing EVs, the number of EVs on the road is forecast to increase 30% in 2026,” said Jonathan Davenport, Sr Director Analyst at Gartner. “In 2026, China is projected to account for 61% of total EV installed base, and global ownership of plug-in hybrid EVs (PHEVs) is expected to rise 32% year-over-year as customers value the reassurance of a back-up petrol engine for use, should they need it.”
The post Gartner Forecasts Having 116 Million EVs on the Road in 2026 appeared first on ELE Times.
Toradex Launches Two New Computer on Module Families for Ultra-Compact Industrial and IoT Applications
Toradex has expanded its embedded computing portfolio with four new modules powered by NXP i.MX 93 and i.MX 91 processors: OSM iMX93, OSM iMX91, and Lino iMX93, Lino iMX91 by launching two entirely new Computer on Module (CoM) families, OSM and Lino.
The OSM and Lino families deliver cost-optimized, industrial-grade reliability, offering ultra-compact form factors, and long-term software support, designed for high-volume, space-constrained industrial IoT devices, like industrial controllers, gateways, smart sensors, and handheld systems, among others. For AI at the Edge, Industrial IoT applications, the NXP i.MX 93 offers a 0.5 TOPS NPU, enabling entry-level HW accelerated on-device machine learning for smart sensing, analytics, and industrial intelligence. Designed for extreme temperatures from -40°C to +85°C, both the OSM and Lino families deliver industrial-grade reliability and availability through 2038, providing a future-proof foundation for next-generation IoT and edge devices.

Both families deliver new compact, reliable, industrial Edge AI compute platforms”, said Samuel Imgrueth, CEO at Toradex. “While OSM adds a solderable standard form factor, Lino provides connector-based ease of use for rapid integration and serviceability. This empowers customers to design next generation, intelligent, space-constrained devices with confidence, scalability, and long-term support.
The OSM family adheres to the Open Standard Module (OSM) Size-S specification, providing a 30 × 30mm solderable, connector-less design optimized for automated assembly, rugged operation, and cost-effective scaling. It’s an ideal choice for high-volume applications up to several hundred thousand devices a year.

The Lino family provides a cost-optimized, connector-based entry point for space-constrained devices. Its easy-to-use connector interface simplifies integration, serviceability, and speeds up development, while rich connectivity options support a wide range of scalable industrial and IoT applications.

Toradex is also introducing the Verdin-Lino Adapter, allowing any Lino module to be mounted onto any Verdin-compatible carrier board. This gives customers immediate access to the powerful Verdin ecosystem and enables testing and validation using both the Verdin Development Board and existing Verdin-based custom designs.

All modules come with full Toradex Software support, including a Yocto Reference Image and Torizon support, a Yocto-based, long-term-supported Linux platform that provides secure OTA remote updates, device monitoring, remote access, and simplified EU CRA (Cyber Resilience Act) compliance. Its integration with Visual Studio Code and rich ecosystem accelerates development while ensuring production reliability and operational security. Torizon is also the ideal starting point for your own Linux Distribution.
The post Toradex Launches Two New Computer on Module Families for Ultra-Compact Industrial and IoT Applications appeared first on ELE Times.
Global IP dynamics highlight surging GaN innovation activity in Q3/2025, says KnowMade
🏰 Запрошуємо на екскурсію «Місто корупційних таємниць: відкрийте правду, яка ховається за фасадами»

14 грудня о 12:00 запрошуємо всіх охочих на екскурсію, яка змінить ваше уявлення про Київ.
Ми пройдемо маршрутами, які зберігають більше, ніж здається на перший погляд, повз будівлі, що могли б розповісти не одну цікаву історію.
The Great Leap: How AI is Reshaping Cybersecurity from Pilot Projects to Predictive Defense
Imagine your cybersecurity team as a group of highly-trained detectives. For decades, they’ve been running through digital crime scenes with magnifying glasses, reacting to the broken window or the missing safe after the fact. Now, suddenly, they have been handed a crystal ball—one that not only detects the threat but forecasts the modus operandi of the attacker before they even step onto the property. That crystal ball is Artificial Intelligence, and the transformation it’s bringing to cyber defense is less a technological upgrade and more a fundamental re-engineering of the entire security operation.
Palo Alto Networks, in partnership with the Data Security Council of India (DSCI), released the State of AI Adoption for Cybersecurity in India report. The report found that only 24% of CXOs consider their organizations fully prepared for AI-driven threats, underscoring a significant gap between adoption intent and operational readiness. The report sets a clear baseline for India Inc., examining where AI adoption stands, what organizations are investing in next, and how the threat landscape is changing. It also surfaces capability and talent gaps, outlines governance, and details preferred deployment models.
While the intent to leverage AI for enhanced cyber defense is almost universal, its operational reality is still maturing. The data reveals a clear gap between strategic ambition and deployed scale.
The report underscores the dual reality of AI: it is a potent defense mechanism but also a primary source of emerging threat vectors. Key findings include:
- Adoption intent is high, maturity is low: 79% of organizations plan to integrate AI/ML towards AI-enabled cybersecurity, but 40% remain in the pilot stage. The main goal is operational speed, prioritizing the reduction of Mean Time to Detect and Respond (MTTD/MTTR).
- Investments are Strategic: 64% of organizations are now proactively investing through multi-year risk-management roadmaps.
- Threats are AI-Accelerated: 23% of the organizations are resetting priorities due to new AI-enabled attack paradigms. The top threats are coordinated multi-vector attacks and AI-poisoned supply chains.
- Biggest Barriers: Financial overhead (19%) and the skill/talent deficit (17%) are the leading roadblocks to adoption.
- Future Defense Model: 31% of organizations consider Human-AI Hybrid Defense Teams as an AI transforming cybersecurity approach and 33% of organizations require human approval for AI-enabled critical security decisions and actions.
“AI is at the heart of most serious security conversations in India, sometimes as the accelerator, sometimes as the adversary itself. This study, developed with DSCI, makes one thing clear: appetite and intent are high, but execution and operational discipline are lagging,” said Swapna Bapat, Vice President and Managing Director, India & SAARC, Palo Alto Networks. “Catching up means using AI to defend against AI, but success demands robustness. Given the dynamic nature of building and deploying AI apps, continuous red teaming of AI is an absolute must to achieve that robustness. It requires coherence: a platform that unifies signals across network, operations, and identity; Zero-Trust verification designed into every step; and humans in the loop for decisions that carry real risk. That’s how AI finally moves from shaky pilots to robust protection.”
Vinayak Godse, CEO, DSCI, said “India is at a critical juncture where AI is reshaping both the scale of cyber threats and the sophistication of our defenses. AI enabled attacker capabilities are rapidly increasing in scale and sophistication. Simultaneously, AI adoption for cyber security can strengthen security preparedness to navigate risk, governance, and operational readiness to predict, detect, and respond to threats in real time. This AI adoption study, supported by Palo Alto Networks, reflects DSCI’s efforts to provide organizations with insights to navigate the challenges emerging out of AI enabled attacks for offense while leveraging AI for security defense.
The report was based on a survey of 160+ organizations across BFSI, manufacturing, technology, government, education, and mid-market enterprises, covering CXOs, security leaders, business unit heads, and functional teams.
The post The Great Leap: How AI is Reshaping Cybersecurity from Pilot Projects to Predictive Defense appeared first on ELE Times.
I know it's nothing crazy but I built this little FM radio board from a kit and I'm proud because it works. I've never soldered before so please don't mind my ugly soldering skills
 | submitted by /u/Cold-Helicopter6534 [link] [comments] |
Just wanted to share the insides of this Securesync 1200 signal generator from 2000s and the option card i installed
 | submitted by /u/jacobson_engineering [link] [comments] |
Bringing up my rosco m68k
 | Hey folks! On my boards the official firmware boots cleanly, the memory checks pass, and UART I/O behaves exactly as it should. I’m using the official rosco tools to verify RAM/ROM mapping, decoding, and the overall bring-up process. I also managed to get a small “hello world” running over serial after sorting out the toolchain with their Docker setup. I’m also tinkering with a 6502 through-hole version — something simple for hands-on exploration of that architecture. Happy to answer any questions or discuss the bring-up process. [link] [comments] |
Weekly discussion, complaint, and rant thread
Open to anything, including discussions, complaints, and rants.
Sub rules do not apply, so don't bother reporting incivility, off-topic, or spam.
Reddit-wide rules do apply.
To see the newest posts, sort the comments by "new" (instead of "best" or "top").
[link] [comments]
My first Smart Socket :)
") | submitted by /u/udfsoft [link] [comments] |
eth industrial switch rx/tx
 | yet still one pair leads to nonexisting chip and second shows only diagnostics from mcu. Life is brutal. [link] [comments] |
Pages


![[link]](https://i.redd.it/uuukn3f0vw5g1.png){kind=link}
![[link]](https://i.redd.it/cali7yzmcj5g1.jpeg){kind=link}