
Збирач потоків
MLPerf and the rise of latency-aware LLM benchmarking

Any discussion of modern AI system performance must include MLCommons and its MLPerf benchmark suite, which has become the industry’s de facto standard for measuring machine learning performance. Since its debut in 2018, MLPerf has provided a neutral, peer-reviewed framework for comparing hardware and software platforms across a broad range of AI workloads.
The original MLPerf benchmarks reflected the dominant AI workloads of the late 2010s. Early inference tests focused on models such as image classification with ResNet-50, natural language processing with Bidirectional Encoder Representations from Transformers (BERT), object detection with RetinaNet, and recommendation with Deep Learning Recommendation Model (DLRM).
These workloads were important and representative at the time, but they shared one characteristic: they were highly parallel and relatively easy to map onto GPU architectures.
For several years, benchmark results reinforced a simple narrative. Each new generation of accelerators delivered higher throughput, lower latency, and better energy efficiency. Because the workloads aligned well with GPU strengths, the benchmark curves rose steadily and predictably.
The generative AI shockwave: Rewriting the rules of MLPerf
Autoregressive LLMs introduced a fundamentally different inference pattern. Prompt processing remained highly parallel, but token generation became sequential and memory bound. Suddenly, raw TeraFLOPS no longer told the whole story.
MLPerf began incorporating this new reality in stages. Inference v4.0 introduced the first LLM benchmark based on Meta platform Llama 2 70B. This benchmark measured token throughput and provided the industry with its first standardized method for comparing LLM inference systems.
MLPerf Inference v5.0 released in 2025 significantly expanded the generative AI focus. It added Llama 3.1 405B Instruct, a 405-billion parameter model with a 128,000-token context window. The benchmark also introduced an interactive variant of Llama 2 70B that imposed strict limits on Time to First Token (TTFT) and Time Per Output Token (TPOT), two metrics that directly capture user experience in conversational applications.
These additions were pivotal because they exposed the core weakness of GPU-based inference systems. When unconstrained by latency, GPUs could buffer requests, create large batches, and deliver excellent throughput. Under interactive latency limits, batching opportunities shrank, hardware utilization dropped, and throughput fell sharply.
In other words, MLPerf began measuring not just how fast a system could run under ideal conditions, but also how responsive it remained under realistic conditions.
Inference disaggregation: Optimization of resources
This evolution reached another milestone in MLPerf Inference v5.1 and the emerging v6.x era. The benchmark suite broadened its focus to include increasingly sophisticated workloads, including reasoning models such as DeepSeek-R1 and more demanding long-context applications. At the same time, submissions began showcasing system-level optimizations such as inference disaggregation, where prompt processing and decoding are assigned to different accelerator pools.
Disaggregation has become one of the most consequential developments in modern inference benchmarking.
Historically, MLPerf treated each benchmark run as a single system under test, leaving vendors free to optimize their hardware and software stacks as they saw fit. As long as submissions complied with accuracy and latency requirements, any architectural technique was fair game.
This openness allowed participants to introduce increasingly sophisticated serving strategies. One of the most effective has been the separation of prefill and generation across distinct groups of accelerators. The prefill cluster handles the compute-intensive prompt processing stage, while the generation cluster focuses exclusively on token decoding.
In controlled benchmark scenarios, where prompt lengths and output lengths are known in advance, disaggregation can produce dramatic gains. By eliminating interference between the two phases, systems reduce preemption and improve latency-sensitive throughput.
Yet this raises an important question. Does the benchmark still measure accelerator capability, or is it increasingly measuring system orchestration? The answer is both.
Modern AI performance depends on the interaction between processor, memory hierarchy, interconnect fabric, runtime software, and serving algorithms. MLPerf has evolved accordingly. It now rewards system-level innovation rather than isolated chip performance.
That shift is entirely appropriate, but it also means benchmark results must be interpreted carefully.
A disaggregated configuration optimized for long document summarization may perform brilliantly in MLPerf while delivering more modest benefits in production environments where workloads vary continuously. Real-world deployments must cope with unpredictable prompt lengths, bursty traffic, and rapidly changing ratios of prefill to generation demand.
Consequently, MLPerf increasingly measures a system’s ability to align resources with a known workload profile. This is a valuable metric, but it’s not synonymous with universal real-world performance.
Illustrative comparison: MLPerf 5.x versus MLPerf 6.x
Table below illustrates how benchmark methodology evolved as MLPerf shifted from throughput-oriented LLM tests to more latency-sensitive and system-aware workloads. The numbers are representative rather than exact, but they reflect the broad trends seen in published results and vendor disclosures.

Publicly discussed MLPerf inference results based on Llama 3.1 405B LLM run on a leading-edge GPU-based processor in three scenarios (off-line, server mode, and interactive mode) highlight MLPerf’s evolution. Source: Author
From chip benchmark to system benchmark
The history of MLPerf mirrors the evolution of AI itself.
The early benchmark suites focused on relatively static workloads that aligned naturally with the strengths of GPU architectures. Tasks such as image recognition, recommendation systems, and conventional deep learning inference relied heavily on dense matrix operations and large-scale parallelism, allowing GPUs to demonstrate exceptional throughput and scalability. In that era, benchmark leadership was closely associated with raw compute capability, memory bandwidth, and increasingly larger accelerator configurations.
The rise of generative AI fundamentally changed that equation.
As autoregressive LLMs became the dominant workload, MLPerf evolved accordingly, introducing larger models, longer context windows, interactive server scenarios, and increasingly strict latency constraints. These additions exposed a critical reality: while GPUs remain extraordinarily efficient during the highly parallel prefill phase, they are far less efficient during token generation, where inference becomes sequential, memory-bound, and heavily dependent on latency-sensitive execution.
This shift transformed the meaning of benchmark performance.
Modern MLPerf results no longer measure the capabilities of an isolated accelerator alone. Instead, they measure the effectiveness of an entire inference architecture.
Disaggregation, scheduling policies, key-value (KV) cache management, streaming pipelines, runtime orchestration, and workload balancing have become just as important as the underlying silicon itself. In many cases, the benchmark winner is no longer the system with the most compute power, but the one that most effectively adapts a fundamentally sequential workload to hardware originally designed for massively parallel graphics and HPC computation.
As a result, benchmark interpretation has become significantly more nuanced. The headline numbers increasingly reflect how intelligently the system orchestrates resources across racks of accelerators, separates prefill from generation, minimizes preemption, and maintains throughput under realistic latency constraints. MLPerf has evolved from a pure hardware benchmark into a broader measure of system architecture and software orchestration.
At the same time, this evolution reveals something even more profound. The latest MLPerf 6.x requirements implicitly highlight the growing limitations of conventional GPU architectures for real-time LLM inference. The industry has reached a point where increasingly sophisticated scheduling mechanisms and disaggregated serving infrastructures are being used to compensate for a deeper architectural mismatch between autoregressive inference and massively parallel processors.
In many respects, the benchmark itself is beginning to suggest the next major transition in AI infrastructure design.
Rather than continuing to optimize architectures originally developed for graphics rendering and parallel numerical computing, the future may require entirely new inference-centric architectures built specifically for the unique characteristics of the LLM generation. Such architectures would need to deliver high utilization and low latency even with very small batch sizes—potentially down to a single user request—while minimizing data movement, reducing memory bottlenecks, and supporting continuous token generation without relying on increasingly complex orchestration layers to hide inefficiencies.
In that sense, MLPerf has become more than a benchmark suite. It is now a window into the architectural tensions shaping the future of AI computing, revealing both the extraordinary adaptability of modern accelerator systems and the growing need for a fundamentally new class of inference hardware designed from the ground up for the realities of autoregressive AI.
Lauro Rizzatti is a business development executive with Vsora, a technology company offering semiconductor solutions that redefine design performance. He is a noted chip design verification consultant and industry expert on hardware emulation.
Editor’s Note
This is Part 2 of the mini-series that examines how LLM inference forced changes to MLPerf benchmarking. In Part 1, contributor Lauro Rizzattti analyzes LLM inference across its two processing phases—prefill versus generation—and highlights how this workflow exposes structural inefficiencies in GPU-based accelerators.
Related Content
- Strategies to Dominate the AI Accelerator Market
- A closer look at LLM’s hyper growth and AI parameter explosion
- The role of AI processor architecture in power consumption efficiency
- AI GPU computing delivers data-center performance on the factory floor
- The truth about AI inference costs: Why cost-per-token isn’t what it seems
The post MLPerf and the rise of latency-aware LLM benchmarking appeared first on EDN.
Advances in core technologies for semiconductor manufacturing
By Tzu-Yi Lee
Revolutionizing semiconductor fabrication, ALD, ALE, and NBE deliver atomic-scale precision, driving unprecedented performance and scalability in next-generation miniaturized devices.
With the rapid growth of the semiconductor industry, Moore’s law has become a core guiding principle for the continuous advancement of electronic devices. Moore’s law predicts that the number of transistors will double every two years, a trend that is driving the continued reduction in device and circuit size. As the size of semiconductor devices shrinks further, the complexity and accuracy of the manufacturing process increase dramatically, requiring the introduction of ultra-precision and ultra-fine technologies into the semiconductor process to ensure device performance and reliability. Among these technologies, etching and deposition are particularly crucial as they form the foundation for achieving high-performance semiconductor devices. They play an essential role in enabling device miniaturization and increasing functional density. Fig. illustrates the trend in semiconductor manufacturing technology from 2000 to 2035, reflecting advancements beyond Moore’s law and incorporating more-than-Moore principles. As transistor technology evolves to Integrated Circuit (IC) evolves, we can see a progression from scale devices and wires to scale basic logic units to scale system functions. Early developments in transistor technology, such as geometric scaling at the 90 nm node, included introducing strained Si and using copper (Cu) for back-end-of-line (BEOL) interconnections. Over time, technological advances drove transistors to 40 nm and 28 nm nodes, when the use of high-k gate dielectrics and metal gate technologies appeared, marking the era of equivalent scaling. With the further development of process technology, from 20 nm to 7 nm, transistor technology entered the era of heterogeneous scaling (post-Moore scaling), which included the widespread use of fin field-effect transistors (FinFETs). FinFETs provide superior channel control due to their three-dimensional structure, which allows the gate to surround the channel on multiple sides, enhancing gate control and reducing short-channel effects. In recent years, the introduction of gate-all-around (GAA) transistors, an advanced technology, has further shrunk device size and provided better control of short-channel effects, reduced leakage current, and enhanced switching performance. As technology nodes advance to 5 nm and beyond, innovations such as GAA transistors provide better control of short-channel effects, reduced leakage, and enhanced performance. Future scaling is expected to incorporate compound field-effect transistors (CFETs), 2D semiconductors, and hybrid integration, which not only sustain Moore’s law but also expand into more-than-Moore functionalities, such as photonic integration, quantum technologies, and neuromorphic computing. These advancements heavily rely on nanoscale etching and deposition processes, such as atomic layer deposition (ALD), atomic layer etching (ALE), and neutral beam etching (NBE), which are critical in achieving the precision and performance required for next-generation devices. This article shows how these advanced techniques drive semiconductor fabrication, supporting continued progress and enabling breakthroughs beyond Moore’s law.
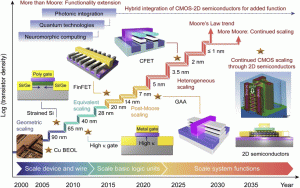
Fig. 1. Evolution of transistor density and gate length in ICs.
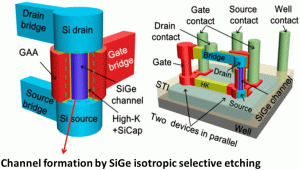
Definition and backgroundThe etching process involves removing a material from a surface through chemical or physical methods, which typically plays a key role in semiconductor manufacturing. Precise control of this process, including major factors such as etch depth, etch profile, surface roughness, and uniformity, is critical to ensuring the performance and reliability of micro- and nanoelectronic devices. Wet etching, which utilizes a chemical reaction in a bath environment, is known for its low cost, ease of implementation, and high material selectivity. Conversely, dry etching is performed through physical and chemical reactions in a vacuum chamber, providing greater precision depth control, profile selectivity, and the ability to define critical feature dimensions.
Atomic layer etching (ALE)ALE is a highly precise technique critical for fabricating nanoscale semiconductor devices. By alternating between adsorption and reaction steps, ALE achieves the removal of single atomic layers per cycle, providing exceptional control and minimizing surface roughness. This method, derived from ALD techniques, involves sequential exposure to different reactive gases, with intermediate purging steps to ensure precise layer-by-layer removal and maintain atomic-scale accuracy. ALE is particularly advantageous in the fabrication of advanced 3D integrated circuits (3D ICs) and memory devices. In 3D IC manufacturing, ALE addresses the challenges of creating complex 3D transistor architectures, such as GAA and multi-bridge-channel FETs (MBCFETs). By enabling atomic-scale etching, ALE provides exceptional control over morphology and depth, ensuring precise patterning for nanoscale features.
Neutral-beam etching (NBE)NBE represents a significant advancement in the etching processes for GaN-based HEMTs and light-emitting diodes (LEDs). This method effectively addresses the critical challenge of plasma-induced damage, which is prevalent in conventional etching techniques such as ICP-RIE. GaN materials are highly valued in the semiconductor industry for high-power and high-frequency applications. However, achieving normally-off operation in GaN-based HEMTs remains challenging due to the plasma-induced damage associated with techniques such as gate recessing. NBE offers a potential solution to minimize such damage and enhance device performance.
Deposition techniquesThin film technology is an advanced approach aimed at improving the structural, electrical, magnetic, optical, and mechanical properties of bulk materials. It has found widespread application in semiconductor devices, integrated circuits, transistors, liquid crystal displays, light-emitting diodes, solar cells, sensors, and micro-electromechanical systems (MEMSs). The distinctive properties of thin film materials are crucial for the technological advancement of various electronic, electrical, magnetic, and optical devices. These films are created using various physical or chemical methods, each of which is essential for producing ultra-thin materials known for their uniform, conformal, and controllable thickness. As atomic and near-atomic scale manufacturing (ACSM) evolves, the necessity of depositing high-quality, impurity-free thin films for laminated structures becomes crucial.
The future of ALD, ALE, and NBE technologies is promising as ongoing advancements continue to address the evolving demands of semiconductor manufacturing. Numerous optimization strategies have been employed to enhance their precision and efficiency. In particular, controlling deposition thickness in ALD, achieving atomic-level etching with ALE, and minimizing surface damage through NBE have proven crucial for improving device performance. Geometrical parameters such as layer thickness, etch depth, and surface passivation have significant impacts on device reliability and durability. Addressing thermal management, particularly in high-power applications, becomes essential as devices scale further. Future efforts could explore the use of more thermally conductive substrates and the refinement of etching profiles to minimize defects and improve device performance. Additionally, optimizing contact technologies to reduce resistance and ensure smooth surface morphology will be critical. Looking ahead, further research should focus on enhancing the uniformity and precision of these processes for advanced applications in micro-LEDs, high-speed communications, and optoelectronics. Future research should consider the performance capabilities of ALD, ALE, and NBE technologies to promote the development of next-generation semiconductor devices.
The post Advances in core technologies for semiconductor manufacturing appeared first on ELE Times.
UP Cabinet Amends 2024 Semiconductor Policy to Boost Investment
The state cabinet on Wednesday approved an amendment to the state’s Semiconductor Policy-2024 to fine-tune and adapt it to specific needs under the India Semiconductor Mission. Officials said the amendment would provide greater flexibility to investors. An official said that the move would accelerate the establishment of semiconductor units, support India’s efforts to build a domestic semiconductor ecosystem, and reduce dependence on imports of critical eleсtronic components. An official spokesperson said that the changes were aimed at providing policy support for investors and aligning the framework with the Centre’s India Semiconductor Mission. The Semiconductor Policy-2024 was notified on Jan 19, 2024, and will remain in force for five years. Officials said that the amendments would not entail any additional financial burden on the state exchequer.
The post UP Cabinet Amends 2024 Semiconductor Policy to Boost Investment appeared first on ELE Times.
Kyocera to acquire Ushio’s laser diode business
Atomera’s MST-enabled GaN-on-Si devices reduce parasitic interface charge by order of magnitude
Covalent expands wafer-level characterization through Oxford Instruments collaboration
КПІшники — серед переможців Всеукраїнської олімпіади з опору матеріалів

Студенти КПІ ім.Ігоря Сікорського найкращі серед 30 студентів із 18 закладів вищої освіти різних міст України. Вітаємо переможців серед студентів другого курсу:
Співпраця з Державною інспекцією архітектури та містобудування України

Підготовка фахівців для відбудови країни, розвитку державних інституцій та сучасної міської інфраструктури. КПІ ім. Ігоря Сікорського співпрацюватиме з Державною інспекцією архітектури та містобудування України.
ElementUSA and Colorado School of Mines awarded $67m by DOE for construction of rare-earth processing plant
Mitsubishi Electric to ship 5th-generation trench SiC MOSFET bare die samples
Homemade PCB with UV mask
 | Finally! I made a perfect pcb on a CNC with a UV mask 🔋. I really love how the copper looks under the mask. [link] [comments] |
Благодійна платформа КПІ ім. Ігоря Сікорського

КПІ ім. Ігоря Сікорського запускає charity.kpi.ua — благодійну платформу для відновлення інфраструктури, підтримки студентів, розвитку науки та збереження найбільшого технічного університету України.
Texas Instruments changes ICs without changing the part number
Hi,
I just encountered this issue with the LP2981 LDO - TI moved to a new fab and "improved" the specs but did not change the ordering code. Seems like you can only identify the difference by some characters on the reel.
Others had the same issue and now even EEV Blog talks about it... with the same issue on a different part.
I only noticed a slight difference on the print of the LP2981 while trying to find out why 80% of the new batch of PCBs are failing.
This seems like an issue with multiple components from TI, so watch out....
[link] [comments]
Memory card interfaces keep pace with the internal bus evolution race: Part 1

Clock speeds get faster. Per-cycle (and per-clock edge) address and data dollops get larger. And protocols get more efficient. But here we’re talking about external, not internal, buses.
Back in 2023, I devoted two blog posts’ worth of content to comparing various memory card technologies, products and speed bin options, initially in March (identifying a fake card in the process) and more in-depth in July. Since then, I’ve come across numerous examples of both evolutionary and revolutionary successors to the devices discussed in that two-part series, not to mention those covered in even more distant-past writeups (themed, for example, around the cameras, digital audio recorders and other devices that leverage such storage).
I’ve had this follow-up piece in my to-do list for a while now, and I’ve finally decided to actualize my longstanding aspiration before the dust pile accumulating on this specific list entry gets any deeper. Not every technology to be discussed in the paragraphs to follow will likely achieve high-volume market success, mind you, with any sooner-or-later failures not necessarily the result of implementation shortcomings, either. Note, for example, that today’s (and past) industry supply constraints encourage manufacturers to “double down” on maximizing the output and profitability of existing approaches, versus devoting scarce capacity to dubious bets.
That said, win or lose there’s usually an interesting story behind each approach. Without further ado…and with the upfront qualifier that I’ll be intentionally delaying any discussion of USB-interface memory devices until later, since their connector locations compel them to be fully external to the system, either sticking straight out of it or cable-tethered to it…and that for related reasons, I won’t be covering eMMC and other fully internal formats, either…and lastly, that I’ll be skipping over legacy formats that were proprietary and/or otherwise non-impactful…
Historical precedentsA short writeup, “History Repeating” at Virginia Tech’s website, begins as follows:
Variations on the repeating-history theme appear alongside debates about attribution. Irish statesman Edmund Burke is often misquoted as having said, “Those who don’t know history are destined to repeat it.” Spanish philosopher George Santayana is credited with the aphorism, “Those who cannot remember the past are condemned to repeat it,” while British statesman Winston Churchill wrote, “Those that fail to learn from history are doomed to repeat it.”
Long-time readers may recall that I’ve referenced variants of this same quote theme in several past writeups, consistently with a negative connotation involving the downsides of ignorance to the past. That said, excessive dependence on history lessons can also be problematic, resulting in evolutionary, overly constraining baby-steps that suppress alternative more revolutionary strides, which may lead to failure but may also dramatically leap beyond traditional approaches.
I’ll leave you to decide for yourselves what to conclude from this first case study, admittedly too personal to likely allow me to be completely arms-length about it! Embedded within the tuple (card identifier) data structures reported by Intel’s Series 2 flash memory cards were the initials of the small team of developers, myself among them, who designed their ASIC (30 years ago…yikes!). I subsequently led the technical marketing launch of the 28F008SA 8 Mbit flash memories inside those same cards, followed by the definition, development and introduction of 16 and 32 Mbit component successors and cards based on them, all in the early-to-mid-1990s.
Products such as these, representing the industry’s first removable and high capacity (for the era, at least) memory cards, added these tuple structures and other enhancements in order to deliver full Personal Computer Memory Card International Association (PCMCIA, later known as PC Card) compatibility, in contrast to Series 1 precursors which were more elementary multi-component arrays along with address decode and chip select logic. Intel’s and others’ similar products were specifically referred to as linear flash memory PC Cards, both to differentiate them from other PCMCIA card types—modems, ISDN and SCSI, for example, and living on (at least to a degree) with CableCARDs—and from alternative ATA-interface flash memory cards.

The key difference between the two memory card types centered on where the flash media management intelligence was located: in the card itself for ATA flash PC Cards, thereby presenting a standardized hardware and software interface to the system regardless of what (and whose) media was inside, versus in the system, implemented as software and/or dedicated hardware, for the linear flash PC card approach. Proponents of the latter scheme touted its claimed reduced media bill-of-materials cost, not to mention the potential ability to direct-execute code out of it (acting as a big parallel-interface chip), but it was inherently relevant for only NOR (vs NAND) memory suppliers, along with being a “heavier lift” for system developers. For these and other reasons, the ATA approach eventually won out in the marketplace.
MiniaturizationThat said, Intel and several of its NOR flash memory partner/competitors had also taken a stab at miniaturizing the linear flash PC Card with the creatively named (ha!) Miniature Card format:

Other flash memory suppliers countered with the ultimately much more popular CompactFlash card, now maintained by the aptly named CompactFlash Association (CFA), whose hardware interface was similarly PCMCIA-derived albeit instead (as with the ATA flash PC Card precursor) focused on the IDE/ATA (and later, UDMA) command set:

Amid this “where is the media management intelligence best located” debate, two other notable contending approaches of the same timeframe also bear mentioning. The first, SmartMedia, was championed by Toshiba (as well as, later, by its primary competitor, Samsung):

SmartMedia was essentially a single (although a few variants embedded multiple) NAND flash memory die embedded within a thin plastic membrane, plus a multi-contact metallic interface that wirebond-direct-connected to the die with no intervening media controller intelligence.
Conceptually sounds like linear flash PC Cards and their derivatives, doesn’t it? Yes…and no. For one thing, SmartMedia was much smaller than either Miniature Card or Compact Flash. For another, it was based on NAND flash memory, which was more HDD-like in its core attributes (notably erase block size and speed) than NOR, simplifying system-side media management development. And then there was the fact that Toshiba wasn’t just a semiconductor supplier; its various systems divisions were potential SmartMedia implementers, and the company also did a good job of cultivating business from other Japanese and broader Asian systems manufacturers.
Finally, near the end of the last century (in 1997, to be exact), Sandisk and systems partners Siemens and Nokia unveiled the MultiMediaCard (MMC), which ultimately came in multiple dimension options, as well as in both standard and clock-boosted performance variants:

MMC is best known today in its aforementioned non-removable eMMC form, which itself is being slowly supplanted by the embedded variant of the MIPI- and SCSI-based Universal Flash Storage (UFS) (an organization whose own removable-version standard ironically has conversely been underwhelmingly adopted by the industry). Today’s generational successor to MMC is the Secure Digital (SD) card, originally referred to as SecureMMC:

which built on the MMC foundation with “enhancements including a digital rights management (DRM) feature, a more durable physical casing, and a mechanical write-protect switch.” The SD standard’s successive iterations have expanded the available clock speed, protocol and electrical contact count options in a backwards-compatible fashion to keep pace with flash memory performance gains, such as in this high-end V90 card from OWC:

The microSD Card derivative tackled substantive dimensional decreases with notable success; here’s one alongside the SmartMedia card I showed you earlier:

One interesting newer SD (and microSD) card specification variation that I became aware of recently when shopping for storage media for a couple of new Raspberry Pi cards is the Application Performance Class. Quoting from Kingston Technology documentation:
A new classification has been presented with the introduction of Android’s Adopted Storage Device feature. The App Performance Class assures minimum random and sequential performance speeds to meet both run and store execution time requirements under given conditions. It does this simultaneously while providing storage for pictures, videos, music, files and other important data. Basically, they’re ideal for use in smartphones and mobile gaming devices that run applications at random read and write speeds while also being used for storage.
There are two ratings for the App Performance Class which are known as A1 and A2. A1 has a minimum random read of 1500 IOPS and a minimum random write of 500 IOPS while A2 has a minimum random read of 4000 IOPS and a minimum random write of 2000 IOPS. Both A1 and A2 have a minimum sustained write speed of 10MB/s. The App Performance Class is something to consider [editor: for example] when planning on installing Android apps on a microSD card.
And, by the way, unlike the SmartMedia competitor of the day, both MMC and successor SD Cards notably also embed (despite their smaller sizes) media management intelligence that simplifies and standardizes the system implementation. Moore’s Law strikes again, eh?
Hang tight; I’ll be right backBelieve it or not, I originally envisioned this being, and wrote it as, a single unified blog post. However, as thought of more (and more…and more…) things to include, the wordcount grew (and grew…and grew…), transforming it into something resembling a small book (I exaggerate, but you get my drift). Having passed through 1,500 words at the beginning of this paragraph, I’m instead going to pause for now, intending (God willing) to share the other half of this now-two-part series with you next week. Until then, please share in the comments your thoughts on what I’ve covered so far!
—Brian Dipert is the associate editor, as well as a contributing editor, at EDN.
Related Content
- Memory cards: Specifications and (more) deceptions
- SD card speeds: question your assumptions
- AI boom and the politics of HBM memory chips
The post Memory card interfaces keep pace with the internal bus evolution race: Part 1 appeared first on EDN.
RTX’s Raytheon awarded $515m contract for GaN-based SPY-6 family of radars
AI data-center expansion to drive monthly capacity of EML and CW-DFB lasers to 50.7 million in 2026
Murata Introduces World’s First 2.2μF/100Vdc Soft-Termination Chip MLCC in 0805-inch Size for Automotive Applications
Murata Manufacturing Co., Ltd. introduces the GCJ21BD72A225KE02, a soft-termination chip multilayer ceramic capacitor (MLCC) for automotive powertrain and safety equipment. This world’s first soft-termination chip MLCC product achieves the highest available capacitance of 2.2μF at 100Vdc in the smallest 0805-inch (2.0×1.25mm) size.
As vehicle electrification accelerates and autonomous driving (AD) and advanced driver-assistance systems (ADAS) grow more sophisticated, engineers face increasing pressure to pack more functionality into tighter board spaces. The wider adoption of 48V power systems further demands components that combine high capacitance, high voltage tolerance, and a small footprint. At the same time, mechanical stress from board flexure, due to vibration and thermal cycling while driving, remains a reliability concern. The GCJ21BD72A225KE02 addresses all these challenges.
Built on Murata’s proprietary ceramic material design, including fine particle size and uniformity control, the soft-termination chip MLCC achieves 2.2μF at 100Vdc in the 0805-inch size, a rating previously only possible in the larger 1206-inch (3.2×1.6mm) size. The result is an approximately 51% reduction in board mounting area compared to Murata’s previous 2.2μF/100Vdc offering, and an approximately 2.2x increase in capacitance over its previous 0805-inch, 100Vdc product. Soft termination further enhances field reliability by absorbing board flexure stress and reducing post-mount cracking.
The GCJ21BD72A225KE02 supports an operating temperature range of -55°C to +125°C and meets X7T temperature characteristics per EIA standards. Murata will continue expanding its automotive-grade MLCC lineup, delivering the miniaturization, high capacitance, high voltage ratings, and reliability that next-generation vehicles demand.
The post Murata Introduces World’s First 2.2μF/100Vdc Soft-Termination Chip MLCC in 0805-inch Size for Automotive Applications appeared first on ELE Times.
ROHM’s 750V SiC MOSFET adopted in battery backup unit for AI servers
Indium Corp and Ames National Lab team to establish US gallium supply chain
Qorvo Eliminates Negative Bias in New RF Control Portfolio
Qorvo, a leading global provider of connectivity and power solutions, announces a new portfolio of silicon-on-insulator (SOI) RF switches and digital step attenuators (DSAs) for defense, aerospace, and infrastructure customers. This new portfolio simplifies RF system design, reduces BOM complexity, and accelerates integration in wideband systems.
These new solutions address growing system demands for broader frequency coverage, agile signal routing, and optimal integration without the complexity of legacy GaAs-based RF control component approaches or multi-vendor RF control chains. With TTL-compatible control that eliminates the need for a negative voltage rail, Qorvo’s SOI portfolio helps designers simplify biasing networks, reduce BOM count, streamline board layouts while maintaining the fast-switching speeds, high isolation, and high linearity required in defense and aerospace applications. The portfolio gives designers a simpler alternative to legacy RF control approaches that require negative bias rails, multiple control components, and more complex board-level integration.
“Customers are looking for ways to simplify RF control architectures without sacrificing the switching speed and RF performance required in modern defense systems,” said Doug Bostrom, general manager of Qorvo’s Defense and Aerospace business. “By eliminating the need for a negative voltage rail, our SOI portfolio helps reduce design complexity, streamline integration, and provide a faster path from design to deployment.”
| Product | Function | Frequency Range | Key Differentiators | Target Applications |
| QPC2320 | Reflective SPDT Switch | Up to 15 GHz | Low insertion loss, high isolation, high linearity, <50 ns switching | Radar, EW, secure communications |
| QPC2420 | Reflective SPDT Switch | Up to 30 GHz | Wideband coverage, high linearity, fast switching, compact footprint | Wideband radar, SATCOM, test & measurement |
| QPC2180 | Reflective SP8T Switch | Up to 8 GHz | High linearity for filter banks, compact integration | Filter banks, multi-band radios |
| QPC5330 | 6-bit Digital Step Attenuator | Up to 15 GHz | Precise attenuation, glitch-safe operation, SPI/I2C control | Signal conditioning, radar/EW |
| QPC5430 | 6-bit Digital Step Attenuator | Up to 30 GHz | Wideband attenuation, high linearity, daisy-chain support | Test & measurement, microwave backhaul, communications systems |
Unlike conventional approaches that rely on multiple narrowband components or mixed-vendor solutions, Qorvo’s SOI portfolio enables designers to standardize switch and attenuator functions into a scalable RF control platform. This reduces routing complexity, minimizes calibration effort, and accelerates design reuse across programs. In comparison to legacy GaAs switches, Qorvo delivers simpler biasing and easier integration while maintaining RF performance for modern defense and aerospace systems. With discrete multi-part RF control chains, designers can reduce BOM complexity, board space, and integration burden while improving signal integrity and simplifying future upgrades.
The portfolio aligns with key industry trends, including wider bandwidth radar and EW systems, more agile signal routing requirements, and increasing pressure to reduce SWaP while accelerating time to market. By combining optimal control integration, fast switching, high isolation, strong linearity, and flexible digital control, Qorvo enables designers to modernize RF control architectures without increasing system complexity.
The post Qorvo Eliminates Negative Bias in New RF Control Portfolio appeared first on ELE Times.
Сторінки

