
Збирач потоків
I hear we like to sort stuff here? How about a gallon of resistance?
 | submitted by /u/mofomeat [link] [comments] |
Weekly discussion, complaint, and rant thread
Open to anything, including discussions, complaints, and rants.
Sub rules do not apply, so don't bother reporting incivility, off-topic, or spam.
Reddit-wide rules do apply.
To see the newest posts, sort the comments by "new" (instead of "best" or "top").
[link] [comments]
NUBURU activates Q1 production ramp for 40 high-power blue laser systems
Звіт першого проректора КПІ Михайла Безуглого на засіданні Вченої ради 12 січня 2026 року

Функціонування університету в умовах визначеної невизначеності: причини для адаптації чи виклик новим можливостям
A tutorial on instrumentation amplifier boundary plots—Part 2

The first installment of this series introduced the boundary plot, an often-misunderstood plot found in instrumentation amplifier (IA) datasheets. It also discussed various IA topologies: traditional three operational amplifier (op amp), two op amp, two op amp with a gain stage, current mirror, current feedback with super-beta transistors, and indirect current feedback.
Part 1 also included derivations of the internal node equations and transfer function of a traditional three-op-amp IA.
The second installment will introduce the input common-mode and output swing limitations of op amps, which are the fundamental building blocks of IAs. Modifying the internal node equations from Part 1 yields equations that represent each op amp’s input common-mode and output swing limitation at the output of the IA as a function of the device’s input common-mode voltage.
The article will also examine a generic boundary plot in detail and compare it to plots from device datasheets to corroborate the theory.
Op-amp limitations
For an op amp to output a linear voltage, the input signal must be within the device’s input common-mode range specification (VCM) and the output (VOUT) must be within the device’s output swing range specification. These ranges depend on the supply voltages, V+ and V– (Figure 1).

Figure 1 Op-amp input common-mode (green) and output swing (red) ranges depend on supplies. Source: Texas Instruments
Figure 2 depicts the datasheet specifications and corresponding VCM and VOUT ranges for an op amp, such as TI’ OPA188, given a ±15V supply. For this device, the output swing is more restrictive than the input common-mode voltage range.

Figure 2 Op-amp VCM and VOUT ranges are shown for a ±15 V supply of the OPA188 op amp. Source: Texas Instruments
The boundary plot
The boundary plot for an IA is a representation of all internal op-amp input common-mode and output swing limitations. Figure 3 depicts a boundary plot. Operating outside the boundaries of the plot violates at least one input common-mode or output swing limitation of the internal amplifiers. Depending on the severity of the violation, the output waveform may depict anything from minor distortion to severe clipping.

Figure 3 Here is how an IA boundary plot looks like for the INA188 instrumentation amplifier. Source: Texas Instruments
This plot is specified for a particular supply voltage (VS = ±15 V), reference voltage (VREF = 0 V), and gain of 1 V/V.
Figure 4 illustrates the linear output range given two different input common-mode voltages. For example, if the common-mode input of the IA is 8 V, the output will be valid only from approximately –11 V to +11 V. If the common-mode input is mid supply (0 V), however, an output swing of ±14.78 V is available.

Figure 4 Output voltage range is shown for different common-mode voltages. Source: Texas Instruments
Notice that the VCM (blue arrows) ranges from –15 V to approximately +13.5 V. Both the mid-supply output swing and VCM ranges are consistent with the op-amp ranges depicted in Figure 2.
Each line in the boundary plot corresponds to a limitation—either VCM or VOUT—of one of the three internal amplifiers. Therefore, it’s necessary to review the internal node equations first derived in Part 1. Figure 5 depicts the standard three-op-amp IA, while Equations 1 through 6 define the voltage at each internal node.

Figure 5 Here is how a three-op-amp IA looks like. Source: Texas Instruments
(1) (2)
(2)  (3)
(3)  (4)
(4)  (5)
(5)  (6)
(6) ![]() In order to plot the node equation limits on a graph with VCM and VOUT axes, solve Equation 6 for VD, as shown in Equation 7:
In order to plot the node equation limits on a graph with VCM and VOUT axes, solve Equation 6 for VD, as shown in Equation 7:
(7) 
Substituting Equation 7 for VD in Equations 1 through 6 and solving for VOUT yields Equations 8 through 13. These equations represent each amplifier’s input common-mode (VIA) and output (VOA) limitation at the output of the IA, and as a function of the device’s input common-mode voltage.
(8) ![]()
(9) ![]()
(10) ![]()
(11) ![]()
(12) ![]()
(13) 
One important observation from Equations 8 and 9 is that the IA limitations from the common-mode range of A1 and A2 depend on the gain of the input stage, GIS. These output limitations do not depend on GIS, however, as shown by Equations 11 and 12.
Plotting each of these equations for the minimum and maximum input common-mode and output swing limitations for each op amp (A1, A2 and A3) yields the boundary plot. Figure 6 depicts a generic boundary plot. The linear operation of the IA is the interior of all plotted equations.

Figure 6 Here is an example of a generic boundary plot. Source: Texas Instruments
The dotted lines in Figure 6 represent the input common-mode limitations for A1 (blue) and A2 (red). Notice that the slope of the dotted lines depends on GIS, which is consistent with Equations 8 and 9.
Solid lines represent the output swing limitations for A1 (blue), A2 (red) and A3 (green). The slope of these lines does not depend on GIS, as shown by Equations 11 through 13.
Figure 6 doesn’t show the line for VIA3 because the R2/R1 voltage divider attenuates the output of A2; A2 typically reaches the output swing limitation before violating A3’s input common-mode range.
The lines plotted in quadrants one and two (positive common-mode voltages) use the maximum input common-mode and output swing limits for A1 and A2, whereas the lines plotted in quadrants three and four (negative common-mode voltages) use the minimum input common-mode and output swing limits.
Considering only positive common-mode voltages from Figure 6, Figure 7 depicts the linear operating region of IA when G = 1 V/V. In this example, the input common-mode limitation of A1 and A2 is more restrictive than the output swing.

Figure 7 The input common-mode range limit of A1 and A2 defines the linear operation region when G = 1 V/V. Source: Texas Instruments
Increasing the gain of the device changes the slope of VIA1 and VIA2 (Figure 8). Now both the input common-mode and output swing limitations define the linear operating region.

Figure 8 The input common-mode range and output swing limits of A1 and A2 define the linear operating range when G > 1 V/V. Source: Texas Instruments
Regardless of gain, the output swing always limits the linear operating region when it’s more restrictive than the input common-mode limit (Figure 9).

Figure 9 The output swing limit of A1 and A2 define the linear operating region independent of gain. Source: Texas Instruments
Datasheet examples
Figure 10 illustrates the boundary plot from the INA111 datasheet. Notice that the output swing limit of A1 and A2 define the linear operating region. Therefore, the output swing limitations of A1 and A2 must be equal to or more restrictive than the input common-mode limitations.

Figure 10 Boundary plot for the INA111 instrumentation amplifier shows output swing limitations. Source: Texas Instruments
Figure 11 depicts the boundary plot from the INA121 datasheet. Notice that the linear operating region changes with gain. At G = 1 V/V, the input common mode must limit the linear operating region. However, as gain increases, the linear operating region is limited by both the output swing and input common-mode limitations (Figure 8).

Figure 11 Boundary plot is shown for the INA121 instrumentation amplifier. Source: Texas Instruments
Third installment coming
The third installment of this series will explain how to use these equations and concepts to develop a tool that automates the drawing of boundary plots. This tool enables you to adjust variables such as supply voltage, reference voltage, and gain to ensure linear operation for your application.
Peter Semig is an applications manager in the Precision Signal Conditioning group at TI. He received his bachelor’s and master’s degrees in electrical engineering from Michigan State University in East Lansing, Michigan.
Related Content
- Instrumentation amplifier input-circuit strategies
- Discrete vs. integrated instrumentation amplifiers
- New Instrumentation Amplifier Makes Sensing Easy
- Instrumentation amplifier VCM vs VOUT plots: part 1
- Instrumentation amplifier VCM vs. VOUT plots: part 2
The post A tutorial on instrumentation amplifier boundary plots—Part 2 appeared first on EDN.
20 Years of EEPROM: Why It Matters, Needed, and Its Future
ST has been the leading manufacturer of EEPROM for the 20th consecutive year. As we celebrate this milestone, we wanted to reflect on why the electrically erasable programmable read-only memory market remains strong, the problems it solves, why it still plays a critical role in many designs, and where we go from here. Indeed, despite the rise in popularity of Flash, SRAM, and other new memory types, EEPROM continues to meet the needs of engineers seeking a compact, reliable memory. In fact, over the last 20 years, we have seen ST customers try to migrate away from EEPROM only to return to it with even greater fervour.
Why companies choose EEPROM today? Granularity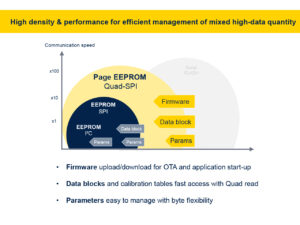 Understanding EEPROM
Understanding EEPROM
One of the main advantages of electrically erasable programmable read-only memory is its byte-level granularity. Whereas writing to other memory types, like flash, means erasing an entire sector, which can range from many bytes to hundreds of kilobytes, depending on the model, an EEPROM is writable byte by byte. This is tremendously beneficial when writing logs, sensor data, settings, and more, as it saves time, energy, and reduces complexity, since the writing operation requires fewer steps and no buffer. For instance, using an EEPROM can save significant resources and speed up manufacturing when updating a calibration table on the assembly line.
PerformanceThe very nature of EEPROM also gives it a significant endurance advantage. Whereas flash can only support read/write cycles in the hundreds of thousands, an EEPROM supports millions, and its data retention is in the hundreds of years, which is crucial when dealing with systems with a long lifespan. Similarly, its low peak current of a few milliamps and its fast boot time of 30 µs mean it can meet the most stringent low-power requirements. Additionally, it enables engineers to store and retrieve data outside the main storage. Hence, if teams are experiencing an issue with the microcontroller, they can extract information from the EEPROM, which provides additional layers of safety.
ConvenienceThese unique abilities explain why automotive, industrial, and many other applications just can’t give up EEPROM. For many, giving it up could break software implementation or require a significant redesign. Indeed, one of the main advantages of EEPROM is that they fit into a small 8-pin package regardless of memory density (from 1 Kbit to 32 Mbit). Additionally, they tolerate high operating temperatures of up to 145 °C for serial EEPROM, making them easy to use in a wide range of environments. The middleware governing their operations is also significantly more straightforward to write and maintain, given their operation.
ResilienceSince ST controls the entire manufacturing process, we can provide greater guarantees to customers facing supply chain uncertainties. Concretely, ST offers EEPROM customers a guarantee of supply availability through our longevity commitment program (10 years for industrial-grade products, 15 years for automotive-grade). This explains why, 40 years after EEPROM development began in 1985 and after two decades of leadership, some sectors continue to rely heavily on our EEPROMs. And why new customers seeking a stable long-term data storage solution are adopting it, bolstered by ST’s continuous innovations, enabling new use cases.
Why will the industry need EEPROM tomorrow? More storage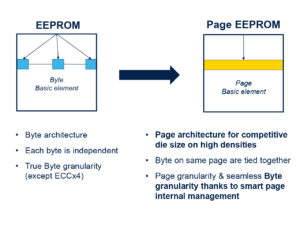 EEPROM vs. Page EEPROM
EEPROM vs. Page EEPROM
Since its inception in the late 70s, EEPROM’s storage has always been relatively minimal. In many instances, it is a positive feature for engineers who want to reserve their EEPROM for small, specific operations and segregate it from the rest of their storage pool. However, as serial EEPROM reached 4 Mbit and 110 nm, the industry wondered whether the memory could continue to grow in capacity while shrinking process nodes. A paper published in 2004 initially concluded that traditional EEPROMs “scale poorly with technology”. Yet, ST recently released a Page EEPROM capable of storing 32 Mbit that fits inside a tiny 8-pin package.
The Page EEPROM adopts a hybrid architecture, meaning it uses 16-byte words and 512-byte pages while retaining the ability to write at the byte level. This offers customers the flexibility and robustness of traditional EEPROM but bypasses some of the physical limitations of serial EEPROM, thus increasing storage and continuing to serve designs that rely on this type of memory while still improving endurance. Indeed, a Page EEPROM supports a cumulative one billion cycles across its entire memory capacity. For many, Page EEPROMs represent a technological breakthrough by significantly expanding data storage without changing the 8-pin package size. That’s why we’ve seen them in asset tracking applications and other IoT applications that run on batteries.
New featuresST also recently released a Unique ID serial EEPROM, which uses the inherent capabilities of electrically erasable programmable read-only memory to store a unique ID or serial number to trace a product throughout its assembly and life cycle. Usually, this would require additional components to ensure that the serial number cannot be changed or erased. However, thanks to its byte-level granularity and read-only approach, the new Unique ID EEPROM can store this serial number while preventing any changes, thus offering the benefits of a secure element while significantly reducing the bill of materials. Put simply, the future of EEPROM takes the shape of growing storage and new features.
The post 20 Years of EEPROM: Why It Matters, Needed, and Its Future appeared first on ELE Times.
Navitas unveils fifth-generation SiC Trench-Assisted Planar MOSFET technology
Modern Cars Will Contain 600 Million Lines of Code by 2027
Courtesy: Synopsys
The 1977 Oldsmobile Toronado was ahead of its time.
Featuring an electronic spark timing system that improved fuel economy, it was the first vehicle equipped with a microprocessor and embedded software. But it certainly wasn’t the last.
While the Toronado had a single electronic control unit (ECU) and thousands of lines of code (LOC), modern vehicles have many ECUs and 300 million LOC. What’s more, the pace and scale of innovation continue to accelerate at an exponential, almost unfathomable rate.
It took half a century for cars to reach 300 million LOC.
We predict the amount of software in vehicles will double in the next 12 months alone, reaching 600 million LOC or more by 2027.
The fusion of automotive hardware and software
Automotive design has historically been focused on structural and mechanical platforms — the chassis and engine. Discrete electronic and software components were introduced over time, first to replace existing functions (like manual window cranks) and later to add new features (like GPS navigation).
For decades, these electronics and the software that define them were designed and developed separately from the core vehicle architecture — standalone components added in the latter stages of manufacturing and assembly.
This approach is no longer viable.
Not with the increasing complexity and interdependence of automotive electronics. Not with the criticality of those electronics for vehicle operation, as well as driver and passenger safety. And not with a growing set of software-defined platforms — from advanced driver assistance (ADAS) and surround view camera systems to self-driving capabilities and even onboard agentic AI — poised to double the amount of LOC in vehicles over the next year.
From the chassis down to the code, tomorrow’s vehicles must be designed, developed, and tested as a single, tightly integrated, highly sophisticated system.
Shifting automotive business models
The rapid expansion of vehicular software isn’t just a technology trend — it’s rewriting the economics of the automotive industry. For more than a century, automakers competed on horsepower, handling, and mechanical innovation. Now, the battleground is shifting to software features, connectivity, and continuous improvement.
Instead of selling a static product, OEMs are adopting new, more dynamic business models where vehicles evolve long after they leave the showroom. Over-the-air updates can deliver new capabilities, performance enhancements, and safety improvements without a single trip to the dealer. And features that used to be locked behind trim levels can be offered as on-demand upgrades or subscription services.
This transition is already underway.
Some automakers are experimenting with monthly fees for heated seats or performance boosts. Others are building proprietary operating systems to replace third-party platforms, giving them control over the user experience — as well as the revenue stream. By the end of the decade, software subscriptions will become as common as extended warranties, generating billions in recurring revenue and fundamentally changing how consumers think about car ownership.
The engineering challenge behind OEM transformation
Delivering on the promise of software-defined vehicles (SDVs) that continuously evolve isn’t as simple as adding more code. It requires a fundamental rethinking of how cars are designed, engineered, and validated.
Hundreds of millions of lines of code must push data seamlessly across a variety of electronic components and systems. And those systems — responsible for sensing, safety, communication, and other functions — must work in concert with millisecond precision.
For years, vehicle architectures relied on dozens of discrete ECUs, each dedicated to a specific function. But as software complexity grows, automakers are shifting toward fewer, more powerful centralised compute platforms that can handle much larger workloads. This means more code is running on less hardware, with more functionality consolidated onto a handful of high-performance processors. As a result, the development challenge is shifting from traditional ECU integration — where each supplier delivered a boxed solution — to true software integration across a unified compute platform.
As such, hardware and software development practices can no longer be separate tracks that converge late in the process. They must be designed together and tailored for one another — well before any physical platform exists.
This is where electronics digital twins (eDTs) are becoming indispensable. By creating functionally accurate virtual models of vehicle electronics and systems, design teams can shift from late-stage integration to a model where software and hardware are co-developed from day one.
eDTs and virtual prototypes do more than enable earlier software development at the component level — they allow engineers to simulate, validate, and optimise the entire vehicle electronics. This means teams can see how data flows across subsystems, how critical components interact under real-world scenarios, and how emerging features might impact overall safety and performance. With eDTs, automakers can test billions — even trillions — of operating conditions and edge cases, many of which would be too costly, too time-consuming, or otherwise infeasible with physical prototypes.
By embracing eDTs, the industry is not just keeping pace with escalating complexity — it is re-engineering longstanding engineering processes, accelerating innovation, and improving the quality and safety of tomorrow’s vehicles.
The road ahead
Our prediction of cars containing 600 million lines of code by 2027 isn’t just a number. It signals a turning point for an industry that has operated in largely the same manner for more than a century.
Many automakers are reimagining their identity.
No longer just manufacturers, they’re becoming technology companies with business models that resemble those of cloud providers and app developers. They’re adopting agile, iterative practices, where updates roll out continuously rather than in multi-year product refreshes. And they’re learning how to design, develop, test, and evolve their products as a unified system — from chassis and engine to silicon and software — rather than a collection of pieces that are assembled on a production line.
Unlike the 1977 Oldsmobile Toronado, the car you buy in 2027 won’t be the same car you drive in 2030 — and that’s by design.
The post Modern Cars Will Contain 600 Million Lines of Code by 2027 appeared first on ELE Times.
Advancement in waveguides to progress XR displays, not GPUs
Across emerging technology domains, a familiar narrative keeps repeating itself. In Extended Reality (XR), progress is often framed as a race toward ever more powerful GPUs. In wireless research, especially around 6G, attention gravitates toward faster transistors and higher carrier frequencies in the terahertz (THz) regime. In both cases, this framing is misleading. The real constraint is no longer raw compute or device-level performance. It is system integration. This is not a subtle distinction. It is the difference between impressive laboratory demonstrations and deployable, scalable products.
XR Has Outgrown the GPU BottleneckIn XR, GPU capability has reached a point of diminishing returns as the primary limiter. Modern graphics pipelines, combined with foveated rendering, gaze prediction, reprojection, and cloud or edge offloading, can already deliver high-quality visual content within reasonable power envelopes. Compute efficiency continues to improve generation after generation. Yet XR has failed to transition from bulky headsets to lightweight, all-day wearable glasses. The reason lies elsewhere: optics, specifically waveguide-based near-eye displays.
Waveguides must inject, guide, and extract light with high efficiency while remaining thin, transparent, and manufacturable. They must preserve colour uniformity across wide fields of view, provide a sufficiently large eye-box, suppress stray light and ghosting, and operate at power levels compatible with eyewear-sized batteries. Today, no waveguide architecture geometric (reflective), diffractive, holographic, or hybrid solves all these constraints simultaneously. This reality leads to a clear conclusion: XR adoption will be determined by breakthroughs in waveguides, not GPUs. Rendering silicon is no longer the pacing factor; optical system maturity is.
The Same Structural Problem Appears in THz and 6GA strikingly similar pattern is emerging in terahertz communication research for 6G. On paper, THz promises extreme bandwidths, ultra-high data rates, and the ability to merge communication and sensing on a single platform. Laboratory demonstrations routinely showcase impressive performance metrics. But translating these demonstrations into real-world systems has proven far harder than anticipated. The question is no longer whether transistors can operate at THz frequencies; they can, but whether entire systems can function reliably, efficiently, and repeatably at those frequencies.
According to Vijay Muktamath, Founder of Sensesemi Technologies, the fundamental bottleneck holding THz radios back from commercialisation is system integration. Thermal management becomes fragile, clock and local oscillator integration grows complex, interconnect losses escalate, and packaging parasitics dominate performance. Each individual block may work well in isolation, but assembling them into a stable system is disproportionately difficult. This mirrors the XR waveguide challenge almost exactly.
When Integration Becomes Harder Than InnovationAt THz frequencies, integration challenges overwhelm traditional design assumptions. Power amplifiers generate heat that cannot be dissipated easily at such small scales. Clock distribution becomes sensitive to layout and material choices. Even millimetre-scale interconnects behave as lossy electromagnetic structures rather than simple wires.
As a result, the question of what truly limits THz systems shifts away from transistor speed or raw output power. Instead, the constraint becomes whether designers can co-optimise devices, interconnects, packaging, antennas, and thermal paths as a single electromagnetic system. In many cases, packaging and interconnect losses now degrade performance more severely than the active devices themselves. This marks a broader transition in engineering philosophy. Both XR optics and THz radios have crossed into a regime where system-level failures dominate component-level excellence.
Materials Are Necessary, But Not SufficientThis raises a critical issue for 6G hardware strategy: whether III–V semiconductor technologies such as InP and GaAs will remain mandatory for THz front ends. Today, their superior electron mobility and high-frequency performance make them indispensable for cutting-edge demonstrations.
However, relying exclusively on III–V technologies introduces challenges in cost, yield, and large-scale integration. CMOS and SiGe platforms, while inferior in peak device performance, offer advantages in integration density, manufacturability, and system-level scaling. Through architectural innovation, distributed amplification, and advanced packaging, these platforms are steadily pushing into higher frequency regimes. The most realistic future is not a single winner, but a heterogeneous architecture. III–V devices will remain essential where absolute performance is non-negotiable, while CMOS and SiGe handle integration-heavy functions such as beamforming, control, and signal processing. This mirrors how XR systems offload rendering, sensing, and perception tasks across specialised hardware blocks rather than relying on a single dominant processor.
Why THz Favours Point-to-Point, Not Cellular CoverageAnother misconception often attached to THz communication is its suitability for wide-area cellular access. While technically intriguing, this vision underestimates the physics involved. THz frequencies suffer from severe path loss, atmospheric absorption, and extreme sensitivity to blockage. Beam alignment overhead becomes significant, especially in mobile scenarios. As Mr Muktamath puts it, “THz is fundamentally happier in controlled environments. Point-to-point links, fixed geometries, short distances, that’s where it shines.”
THz excels in short-range, P2P links where geometry is controlled and alignment can be maintained. Fixed wireless backhauls; intra-data-centre communication, chip-to-chip links, and high-resolution sensing are far more realistic early applications. These use cases resemble the constrained environments where XR has found initial traction in enterprise, defence, and industrial deployments— rather than mass consumer adoption.
Packaging: The Silent DominatorPerhaps the clearest parallel between XR waveguides and THz radios lies in packaging. In XR, the waveguide itself is the package: it dictates efficiency, form factor, and user comfort. In THz systems, packaging and interconnects increasingly dictate whether the system works at all. Losses introduced by packaging can erase transistor-level gains. Thermal resistance can limit continuous operation. Antenna integration becomes inseparable from the RF front-end. This has forced a shift from chip- centric design to electromagnetic system design, where silicon, package, antenna, and enclosure are co-designed from the outset.
Communication and Sensing: Convergence with ConstraintsTHz also revives the idea of joint communication and sensing on shared hardware. In theory, high frequencies offer exceptional spatial resolution, making simultaneous data transmission and environmental sensing attractive. In practice, coexistence introduces non-trivial trade-offs.
Waveform design, dynamic range, calibration, and interference management all become more complex when reliability and throughput must be preserved. The most viable path is not full hardware unification, but carefully partitioned coexistence, with shared elements where feasible and isolation where necessary. This echoes XR architectures, where sensing and rendering share infrastructure but remain logically separated to maintain performance.
A Single Lesson Across Two DomainsXR waveguides and THz radios operate in different markets, but they are constrained by the same fundamental truth: the era of component-led innovation is giving way to system-led engineering. Faster GPUs do not solve optical inefficiencies. Faster transistors do not solve packaging losses, thermal bottlenecks, or integration fragility.
As Mr. Muktamath aptly concludes, “The future belongs to teams that can make complex systems behave simply, not to those who build the most impressive individual blocks.” The next generation of technology leadership will belong to organisations that master cross-domain co-design across devices, packaging, optics, and software. Manufacturability and yield as first-order design constraints, Thermal and power integrity as architectural drivers and Integration discipline over isolated optimisation. In both XR and THz, success will not come from building the fastest block, but from making the entire system work reliably, repeatedly, and at scale. That is the real frontier now.
The post Advancement in waveguides to progress XR displays, not GPUs appeared first on ELE Times.
AI-Enabled Failure Prediction in Power Electronics: EV Chargers, Inverters, and SMPS
Reliability is now a defining parameter for modern power electronic systems. As the world pushes harder toward electric mobility, renewable energy adoption, and high-efficiency digital infrastructure, key converters like EV chargers, solar inverters, and SMPS are running in incredibly demanding environments. High switching frequencies, aggressive power densities, wide bandgap materials (like SiC/GaN), and really stringent uptime expectations have all squeezed those reliability margins down to almost nothing. Clearly, traditional threshold-based alarms or basic periodic maintenance are no longer enough to guarantee stable operation.
This is exactly where AI-enabled failure prediction emerges as a breakthrough. By integrating real-time sensing, historical stress patterns, physics-based models, and deep learning, AI unlocks the ability to spot early degradation. This gives us the power to accurately estimate remaining useful life (RUL) and prevent catastrophic breakdowns long before they ever occur.
Jean‑Marc Chéry, CEO of STMicroelectronics, has emphasised that the practical value of AI in power electronics emerges at fleet and lifecycle scale rather than at individual-unit prediction level, particularly for SiC- and GaN-based SMPS.
Aggregated field data across large deployments is used to refine derating guidelines, validate device-level reliability models, and harden next-generation power technologies, instead of attempting deterministic failure prediction on a per-unit basis.
Limitations of Traditional Monitoring in Power Electronics
Conventional condition monitoring methods, things like simple temperature alarms, current protection limits, or basic event logs, operate reactively. They only catch failures after components have already drifted past the acceptable redline. Yet, converter failures actually start much earlier from subtle, long-term changes. Think about:
- Gradual ESR (Equivalent Series Resistance) increase in electrolytic capacitors
- Bond wire fatigue and solder joint cracking inside IGBT/MOSFET modules
- Gate oxide degradation in newer SiC devices
- Magnetic core saturation and insulation ageing
- Switching waveform distortions caused by gate driver drift
AI Techniques Powering Predictive Failure Intelligence
AI-based diagnostics in power electronics rest on three complementary pillars:
- Deep Learning for Real-Time Telemetry
AI-based diagnostics in power electronics rely on three complementary pillars:
Deep Learning for Real Time Telemetry Converters pump out rich telemetry data: temperatures, currents, switching waveforms, harmonics, soft switching behaviour, and acoustic profiles. Deep learning models find patterns here that are absolutely impossible for a human to spot manually.
- CNNs (Convolutional Neural Networks): These analyse switching waveforms, spot irregularities in turn-on/turn-off cycles, identify diode recovery anomalies, and classify abnormal transient events instantly.
- LSTMs (Long Short Term Memory Networks): These track the long-term drift in junction temperature, capacitor ESR, cooling efficiency, and load cycle behaviour over months.
- Autoencoders: learn the “healthy signature” of a converter and identify deviations that signal emerging faults.
- Physics-Informed ML
Pure machine learning struggles with operating points it has not seen; physics-informed machine learning offers better generalisation. It integrates:
- Power cycle fatigue equations
- MOSFET/IGBT thermal models
- Magnetics core loss equations
- Capacitor degradation curves
- SiC/GaN stress lifetime relationships
Peter Herweck, former CEO of Schneider Electric, has underscored that long-life power conversion systems cannot rely on data-driven models alone.
In solar and industrial inverters, Schneider Electric’s analytics explicitly anchor AI models to thermal behaviour, power-cycling limits, and component ageing physics, enabling explainable and stable Remaining Useful Life estimation across wide operating conditions.
- Digital Twins & Edge AI
Digital twins act as virtual replicas of converters, simulating electrical, thermal, and switching behaviour in real time. AI continuously updates the twin using field data, enabling:
- Dynamic stress tracking
- Load-cycle-based lifetime modelling
- Real-time deviation analysis
- Autonomous derating or protective responses
Edge-AI processors integrated into chargers, inverters, or SMPS enable on-device inference even without cloud connectivity.
AI-Driven Failure Prediction in EV Chargers
EV fast chargers (50 kW–350 kW+) operate under harsh conditions with high thermal and electrical stress. Uptime dictates consumer satisfaction, making predictive maintenance critical.
Key components under AI surveillance
- SiC/Si MOSFETs and diodes
- Gate drivers and isolation circuitry
- DC-link electrolytic and film capacitors
- Liquid/air-cooling systems
- EMI filters, contactors, and magnetic components
Roland Busch, CEO of Siemens, has emphasised that reliability in power-electronic infrastructure depends on predictive condition insight rather than reactive protection.
In high-power EV chargers and grid-connected converters, Siemens’ AI-assisted monitoring focuses on detecting long-term degradation trends—thermal cycling stress, semiconductor wear-out, and DC-link capacitor ageing—well before protection thresholds are reached.
AI-enabled predictive insights
- Waveform analytics: CNNs detect micro-oscillations in switching transitions, indicating gate driver degradation.
- Thermal drift modelling: LSTMs predict MOSFET junction temperature rise under high-power cycling.
- Cooling system performance: Autoencoders identify airflow degradation, pump wear, or radiator clogging.
- Power-module stress estimation: Digital twins estimate cumulative thermal fatigue and RUL.
Charging network operators report a 20–40% reduction in unexpected downtime by implementing AI-enabled diagnostics.
Solar & Industrial Inverters: Long-Life Systems Under Environmental Stress
Solar inverters operate for 10–20 years in harsh outdoor conditions—dust, high humidity, temperature cycling, and fluctuating PV generation.
Common failure patterns identified by AI
- Bond-wire lift-off in IGBT modules due to repetitive thermal stress
- Capacitor ESR drift affecting DC-link stability
- Transformer insulation degradation
- MPPT (Maximum Power Point Tracking) anomalies due to sensor faults
- Resonance shifts in LCL filters
AI-powered diagnostic improvements
- Digital twin comparisons highlight deviations in thermal behaviour or DC-link ripple.
- LSTM RUL estimation predicts when capacitors or IGBTs are nearing end-of-life.
- Anomaly detection identifies non-obvious behavior such as partial shading impacts or harmonic anomalies.
SMPS: High-Volume Applications Where Reliability Drives Cost Savings
SMPS units power everything from telecom towers to consumer electronics. With millions of units deployed, even a fractional improvement in reliability creates massive financial savings.
AI monitors key SMPS symptoms
- Switching frequency drift due to ageing components
- Hotspot formation on magnetics
- Acoustic signatures of transformer failures
- Leakage or gate-charge changes in GaN devices
- Capacitor health degradation trends
Manufacturers use aggregated fleet data to continuously refine design parameters, enhancing long-term reliability.
Cross-Industry Benefits of AI-Enabled Failure Prediction
Industries implementing AI-based diagnostics report:
- 30–50% reduction in catastrophic failures
- 25–35% longer equipment lifespan
- 20–30% decline in maintenance expenditure
- Higher uptime and service availability
Challenges and Research Directions
Even with significant progress, several challenges persist:
- Scarcity of real-world failure data: Failures occur infrequently; synthetic data and stress testing are used to enrich datasets.
- Model transferability limits: Variations in topology, gate drivers, and cooling systems hinder direct model reuse.
- Edge compute constraints: Deep models often require compression and pruning for deployment.
- Explainability requirements: Engineers need interpretable insights, not just anomaly flags.
Research in XAI, transfer learning, and physics-guided datasets is rapidly addressing these concerns.
The Future: Power Electronics Designed with Built-In Intelligence
In the coming decade, AI will not merely monitor power electronic systems—it will actively participate in their operation:
- AI-adaptive gate drivers adjusting switching profiles in real time
- Autonomous derating strategies extending lifespan during high-stress events
- Self-healing converters recalibrating to minimise thermal hotspots
- Cloud-connected fleet dashboards providing RUL estimates for entire EV charging or inverter networks
- WBG-specific failure prediction models tailored for SiC/GaN devices
Conclusion
AI-enabled failure prediction is completely transforming the reliability of EV chargers, solar inverters, and SMPS systems. Engineers are now integrating sensor intelligence, deep learning, physics-based models, and digital twin technology. This allows them to spot early degradation, accurately forecast future failures, and effectively stretch the lifespan of the equipment.
This whole predictive ecosystem doesn’t just cut your operational cost; it significantly boosts system safety, availability, and overall performance. As electrification accelerates, AI-driven reliability will become the core foundation of next-generation power electronic design. It makes systems smarter, more resilient, and truly future-ready.
The post AI-Enabled Failure Prediction in Power Electronics: EV Chargers, Inverters, and SMPS appeared first on ELE Times.
📰 Газета "Київський політехнік" № 5-6 за 2026 (.pdf)
")
Вийшов 5-6 номер газети "Київський політехнік" за 2026 рік
Powering AI: How Power Pulsation Buffers are transforming data center power architecture
Courtesy: Infineon Technologies
Microsoft, OpenAI, Google, Amazon, NVIDIA, etc. are racing against each other, and it is for good reasons: to build massive data centres with billions of dollars in investments.
Imagine a data centre humming with thousands of AI GPUs, each demanding bursts of power like a Formula 1 car accelerating out of a corner. Now imagine trying to feed that power without blowing out the grid.
That is the challenge modern AI server racks face, and Infineon’s Power Pulsation Buffer (PPB) might just be the pit crew solution you need.
Why AI server power supply needs a rethink
As artificial intelligence continues to scale, so does the power appetite of data centres. Tech giants are building AI clusters that push rack power levels beyond 1 MW. These AI PSUs (power supply units) are not just hungry. They are unpredictable, with GPUs demanding sudden spikes in power that traditional grid infrastructure struggles to handle.
These spikes, or peak power events, can cause serious stress on the grid, especially when multiple GPUs fire up simultaneously. The result? Voltage drops, current overshoots, and a grid scrambling to keep up.
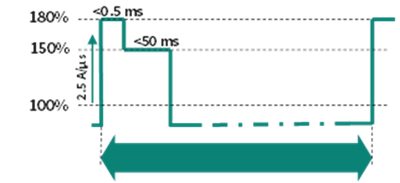 Figure 1: Example peak power profile demanded by AI GPUs
Figure 1: Example peak power profile demanded by AI GPUs
Rethinking PSU architecture for AI racks
To tackle this, next-gen server racks are evolving. Enter the power sidecar, a dedicated module housing PSUs, battery backup units (BBUs), and capacitor backup units (CBUs). This setup separates power components from IT components, allowing racks to scale up to 1.3 MW.
But CBUs, while effective, come with trade-offs:
- Require extra shelf space
- Need communication with PSU shelves
- Add complexity to the rack design
This is where PPBs come in.
What is a Power Pulsation Buffer?
Think of PPB as a smart energy sponge. It sits between the PFC voltage controller and the DC-DC converter inside the PSU, soaking up energy during idle times and releasing it during peak loads. This smooths out power demands and keeps the grid happy.
PPBs can be integrated directly into single-phase or three-phase PSUs, eliminating the need for bulky CBUs. They use SiC bridge circuits rated up to 1200 V and can be configured in 2-level or 3-level designs, either in series or parallel.
PPB vs. traditional PSU
In simulations comparing traditional PSUs with PPB-enhanced designs, the difference is striking. Without PPB, the grid sees a sharp current overshoot during peak load. With PPB, the PSU handles the surge internally, keeping grid power limited to just 110% of rated capacity.
This means:
- Reduced grid stress
- Stable input/output voltages
Better energy utilisation from PSU bulk capacitors
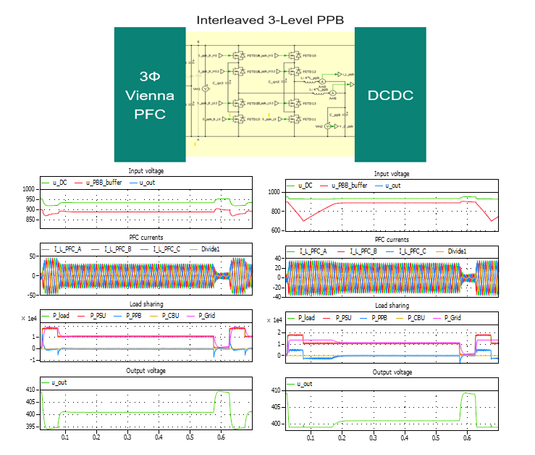 Figure 3: Simulation of peak load event: Without PPB (left) and with PPB (right) in 3-ph HVDC PSU
Figure 3: Simulation of peak load event: Without PPB (left) and with PPB (right) in 3-ph HVDC PSU
PPB operation modes
PPBs operate in two modes, on-demand and continuous. Each is suited to different rack designs and power profiles.
- On-demand operation: Activates only during peak events, making it ideal for short bursts. It minimises energy loss and avoids unnecessary grid frequency cancellation
- Continuous operation: By contrast, always keeps the PPB active. This supports steady-state load jumps and enables DCX with fixed frequency, which is especially beneficial for 1-phase PSUs.
Choosing the right mode depends on the specific power dynamics of your setup.
Why PPB is a game-changer for AI infrastructure
PPBs are transforming AI server power supply design. They manage peak power without grid overload and integrate compactly into existing PSU architectures.
By enhancing energy buffer circuit performance and optimising bulk capacitor utilisation, PPBs enable scalable designs for high-voltage DC and 3-phase PSU setups.
Whether you are building hyperscale data centres or edge AI clusters, PPBs offer a smarter, grid-friendly solution for modern power demands.
The post Powering AI: How Power Pulsation Buffers are transforming data center power architecture appeared first on ELE Times.
AI-powered MCU elevates vehicle intelligence

The Stellar P3E automotive MCU from ST features built-in AI acceleration, enabling real-time AI applications at the edge. Designed for the next generation of software-defined vehicles, it simplifies multifunction integration, supporting X-in-1 electronic control units from hybrid/EV systems to body zonal architectures.

According to ST, the Stellar P3E is the first automotive MCU with an embedded neural network accelerator. Its Neural-ART accelerator, a dedicated neural processing unit (NPU) with an advanced data-flow architecture, offloads AI workloads from the main cores, speeding up inference execution and delivering real-time, AI-based virtual sensing.
The MCU incorporates 500-MHz Arm Cortex-R52+ cores, delivering a CoreMark score exceeding 8000 points. Its split-lock feature lets designers balance functional safety with peak performance, while smart low-power modes go beyond conventional standby. The device also includes extensible xMemory, with up to twice the density of standard embedded flash, plus rich I/O interfaces optimized for advanced motor control.
Stellar P3E production is scheduled to begin in the fourth quarter of 2026.
The post AI-powered MCU elevates vehicle intelligence appeared first on EDN.
Gate drivers emulate optocoupler inputs

Single-channel isolated gate drivers in the 1ED301xMC121 series from Infineon are pin-compatible replacements for optocoupler-based designs. They replicate optocoupler input characteristics, enabling drop-in use without control circuit changes, while using non-optical isolation internally to deliver higher CMTI and improved switching performance for SiC applications.

Their opto-emulator input stage uses two pins and integrates reverse voltage blocking, forward voltage clamping, and an isolated signal transmitter. With CMTI exceeding 300 kV/µs, 40-ns propagation delay, and 10-ns part-to-part matching, the devices deliver robust, high-speed switching performance.
The series includes three variants—1ED3010, 1ED3011, and 1ED3012—supporting Si and SiC MOSFETs as well as IGBTs. Each delivers up to 6.5 A of output current to drive power modules and parallel switch configurations in motor drives, solar inverters, EV chargers, and energy storage systems. The drivers differ in UVLO thresholds: 8.5 V, 11 V, and 12.5 V for the 1ED3010, 1ED3011, and 1ED3012, respectively.
The 1ED3010MC121, 1ED3011MC121, and 1ED3012MC121 drivers are available in CTI 600, 6-pin DSO packages with more than 8 mm of creepage and clearance.
The post Gate drivers emulate optocoupler inputs appeared first on EDN.
IC enables precise current sensing in fast control loops

Allegro Microsystems’ ACS37017 Hall-effect current sensor achieves 0.55% typical sensitivity error across temperature and lifetime. High accuracy, a 750‑kHz bandwidth, and a 1‑µs typical response time make the ACS37017 suitable for demanding control loops in automotive and industrial high-voltage power conversion.

Unlike conventional sensors whose accuracy suffers from drift, the ACS37017 delivers long-term stability through a proprietary compensation architecture. This technology maintains precise measurements, ensuring control loops remain stable and efficient throughout the operating life of the vehicle or power supply.
The ACS37017 features an integrated non-ratiometric voltage reference, simplifying system architecture by eliminating the need for external precision reference components. This integration reduces BOM costs, saves board space, and removes a major source of system-level noise and error.
The high-accuracy ACS37017 expands Allegro’s current sensor portfolio, complementing the ACS37100 (optimized for speed) and the ACS37200 (optimized for power density). Request the preliminary datasheet and engineering samples on the product page linked below.
The post IC enables precise current sensing in fast control loops appeared first on EDN.
Microchip empowers real-time edge AI

Microchip provides a full-stack edge AI platform for developing and deploying production-ready applications on its MCUs and MPUs. These devices operate at the network edge, close to sensors and actuators, enabling deterministic, real-time decision-making. Processing data locally within embedded systems reduces latency and improves security by limiting cloud connectivity.

The full-stack application portfolio includes pretrained, production-ready models and application code that can be modified, extended, and deployed across target environments. Development and optimization are performed using Microchip’s embedded software and ML toolchains, as well as partner ecosystem tools. Edge AI applications include:
- AI-based detection and classification of electrical arc faults using signal analysis
- Condition monitoring and equipment health assessment for predictive maintenance
- On-device facial recognition with liveness detection for secure identity verification
- Keyword spotting for consumer, industrial, and automotive command-and-control interfaces
Microchip is working with customers deploying its edge AI solutions, providing model training guidance and workflow integration across the development cycle. The company is also collaborating with ecosystem partners to expand available software and deployment options. For more information, visit the Microchip Edge AI page.
The post Microchip empowers real-time edge AI appeared first on EDN.
AI agent automates front-end chip workflows

Cadence has launched the ChipStack AI Super Agent, an agentic AI solution for front-end silicon design and verification. The platform automates key design and test workflows—including coding, test plan creation, regression testing, debugging, and issue resolution—offering significant productivity gains for chip development teams. It leverages multiple AI agents that work alongside Cadence’s existing EDA tools and AI-based optimization solutions.

The ChipStack AI Super Agent supports both cloud-based and on-premises AI models, including NVIDIA NeMo models that can be customized for specific workflows, as well as OpenAI GPT. By combining agentic AI orchestration with established simulation, verification, and AI-assistant tools, the platform streamlines complex semiconductor workflows.
Early deployments at leading semiconductor companies have demonstrated measurable reductions in verification time and improvements in workflow efficiency. The platform is currently available in early access for customers looking to integrate AI-driven automation into front-end chip design and verification processes.
Additional information about the ChipStack AI Super Agent can be found on the Cadence AI for Design page.
The post AI agent automates front-end chip workflows appeared first on EDN.
Київська політехніка спільно з Українсько-Японським центром КПІ розпочинає співпрацю з Digital Knowledge Co., Ltd

🇯🇵🇺🇦📃Меморандум про співпрацю з японською компанією, що розробляє платформи для онлайн-курсів, забезпечує розробку, впровадження й підтримку рішень для онлайн-навчання, відкриває нові можливості в секторі цифрової освіти.
Wearables for health analysis: A gratefulness-inducing personal experience

What should you do if your wearable device tells you something’s amiss health-wise, but you feel fine? With this engineer’s experience as a guide, believe the tech and get yourself checked.
Mid-November was…umm…interesting. After nearly two days with an elevated heart rate, which I later realized was “enhanced” by cardiac arrhythmia, I ended up overnighting at a local hospital for testing, medication, procedures, and observation. But if not for my wearable devices, I never would have known I was having problems, to my potentially severe detriment.
I felt fine the entire time; the repeated alerts coming from my smart watch and smart ring were my sole indication to seek medical attention. I’ve conceptually discussed the topic of wearables for health monitoring plenty of times in the past. Now, however, it’s become deeply personal.
Late-night, all-night alertsSunday evening, November 16, 2025, my Pixel Watch smartwatch began periodically alerting me to an abnormally high heart rate. As you can see from the archived reports from Fitbit (the few-hour data gaps each day reflect when the Pixel Watch is on the charger instead of my wrist):
![]()
![]()
![]()
and my Oura Ring 4:



for the prior two days, my normal sleeping heart rate is in the low-to-mid 40s bpm (beats per minute) range. However, during the November 16-to-17 overnight cycle, both wearable devices reported that I was spiking the mid-140s, along with a more general bpm elevation-vs-norm:
![]()

![]()

By Monday evening, I was sufficiently concerned that I shared with my wife what was going on. She recommended that in addition to continued monitoring of my pulse rate and trend, I should also use the ECG (i.e., EKG, for electrocardiogram) app that was built into her Apple Watch Ultra. I first checked to see whether there was a similar app on my Pixel Watch. And indeed, there was: Fitbit ECG. A good overview video is embedded within some additional product documentation:
Here’s an example displayed results screenshot directly from my watch, post-hospital visit, when my heart was once again thankfully beating normally:

I didn’t think to capture screenshots that Monday night—my thoughts were admittedly on other, more serious matters—but here’s a link to the Fitbit-generated November 17 evening report as a PDF, and here’s the captured graphic:

The average bpm was 110. And the report summary? “Atrial Fibrillation: Your heart rhythm shows signs of atrial fibrillation (AFib), an irregular heart rhythm.”
The next morning (PDF, again), when I re-did the test:
![]()


my average bpm was now 140. And the conclusion? “Inconclusive high heart rate: If your heart rate is over 120 beats per minute, the ECG app can’t assess your heart rhythm.”
The data was even more disconcerting this time, and the overall trend was in a discouraging direction. I promptly made an emergency appointment for that same afternoon with my doctor. She ran an ECG on the office equipment, whose results closely (and impressively so) mirrored those from my Pixel Watch. Then she told me to head directly to the closest hospital; had my wife not been there to drive me, I probably would have been transported in an ambulance.
Thankfully, as you may have already noticed from the above graphs, after bouts of both atrial flutter and fibrillation, my heart rate began to return to its natural rhythm by late that same evening. Although the Pixel Watch battery had died by ~6 am on Wednesday morning, my recovery was already well away:
![]()
and the Oura Ring kept chugging along to document the normal heartbeat restoration process:

I was discharged on Wednesday afternoon with medication in-hand, along with instructions to make a follow-up appointment with the cardiologist I’d first met at the hospital emergency room. But the “excitement” wasn’t yet complete. The next morning, my Pixel Watch started yelling at me again, this time because my heart rate was too low:
![]()

My normal resting heart rate when awake is in the low-to-mid 50s. But now it was ~10 points below that. I had an inkling that the root cause might be a too-high medication dose, and a quick call to the doctor confirmed my suspicion. Splitting each tablet in two got things back to normal:
![]()

![]()

As I write this, I’m nearing the end of a 30-day period wearing a cardiac monitor; a quite cool device, the details of which I’ll devote to an upcoming blog post. My next (and ideally last) cardiologist appointment is a month away; I’m hopeful that this arrhythmia event was a one-time fluke.
Regardless, my unplanned hospital visit, specifically the circumstances that prompted it, was more than a bit of a wakeup call for this former ultramarathoner and broader fitness activity aficionado (admittedly a few years and a few pounds ago). And that said, I’m now a lifelong devotee and advocate of smart watches, smart rings and other health monitoring wearables as effective adjuncts to traditional symptoms that, as my case study exemplifies, might not even be manifesting in response to an emerging condition…assuming you’re paying sufficient ongoing attention to your body to be able to notice them if they were present.
Thoughts on what I’ve shared today? As always, please post ‘em in the comments!
—Brian Dipert is the Principal at Sierra Media and a former technical editor at EDN Magazine, where he still regularly contributes as a freelancer.
Related Content
- Wearable trends: a personal perspective
- The Pixel Watch: An Apple alternative with Google’s (and Fitbit’s) personal touch
- The Smart Ring: Passing fad, or the next big health-monitoring thing?
- The Oura Ring 4: Does “one more” deliver much (if any) more?
The post Wearables for health analysis: A gratefulness-inducing personal experience appeared first on EDN.
How to design a digital-controlled PFC, Part 2

In Part 1 of this article series, I explained the system block diagram and each of the modules of digital control. In this second installment, I’ll talk about how to write firmware to implement average current-mode control.
Average current-mode control
Average current-mode control, as shown in Figure 1, is common in continuous-conduction-mode (CCM) power factor correction (PFC). It has two loops: a voltage loop that works as an outer loop and a current loop that works as an inner loop. The voltage loop regulates the PFC output voltage (VOUT) and provides current commands to the current loop. The current loop forces the inductor current to follow its reference, which is modulated by the AC input voltage.
 Figure 1 Average current-mode control is common in CCM PFC, where a voltage loop regulates the PFC output voltage and provides current commands to the current loop. Source: Texas Instruments
Figure 1 Average current-mode control is common in CCM PFC, where a voltage loop regulates the PFC output voltage and provides current commands to the current loop. Source: Texas Instruments
Normalization
Normalizing all of the signals in Figure 1 will enable the ability to handle different signal scales and prevent calculations from overflowing.
For VOUT, VAC, and IL, multiply their analog-to-digital converter (ADC) reading by a factor of , (assuming a 12-bit ADC):
![]() For VREF, multiply its setpoint by a factor of):
For VREF, multiply its setpoint by a factor of):

where R1 and R2 are the resistors used in Figure 4 from Part 1 of this article series.
After normalization, all of the signals are in the range of (–1, +1). The compensator GI output d is in the range of (0, +1), where 0 means 0% duty and 1 means 100% duty.
Digital voltage-loop implementation
As shown in Figure 1, an ADC senses VOUT for comparison to VREF. Compensator GV processes the error signal, which is usually a proportional integral (PI) compensator, as I mentioned in Part 1. The output of this PI compensator will become part of the current reference calculations.
VOUT has a double-line frequency, which couples to the current reference and affects total harmonic distortion (THD). To reduce this ripple effect, set the PFC voltage-loop bandwidth much lower than the AC frequency; for example, around 10Hz. This low voltage-loop bandwidth will cause VOUT to dip too much when a heavy load is applied, however.
Meeting the load transient response requirement will require a nonlinear voltage loop. When the voltage error is small, use a small Kp, Ki gain. When the error exceeds a threshold, using a larger Kp, Ki gain will rapidly bring VOUT back to normal. Figure 2 shows a C code example for this nonlinear voltage loop.

Figure 2 C code example for this nonlinear voltage-loop gain. Source: Texas Instruments
Digital current-loop implementation takes 3 steps:
Step 1: Calculating the current reference
As shown in Figure 1, Equation 3 calculates the current-loop reference, IREF:
![]()
where A is the voltage-loop output, C is the AC input voltage a,nd B is the square of the AC root-mean-square (RMS) voltage.
Using the AC line-measured voltage subtracted by the AC neutral-measured voltage will obtain the AC input voltage (Equation 4 and Figure 3):
![]()

Figure 3 VAC calculated by subtracting AC neutral-measured voltage from AC line-measured voltage. Source: Texas Instruments
Equation 5 defines the RMS value as:

With Equation 6 in discrete format:
![]()
where V(n) represents each ADC sample, and N is the total number of samples in one AC cycle.
After sampling VAC at a fixed speed, it is squared, then accumulated in each AC cycle. Dividing the number of samples in one AC cycle calculates the square of the RMS value.
In steady state, you can treat both voltage-loop output A and the square of VAC RMS value B as constant; thus, only C (VAC) modulates IREF. Since VAC is sinusoidal, IREF is also sinusoidal (Figure 4).

Figure 4 Sinusoidal current reference IREF due to sinusoidal VAC. Source: Texas Instruments
Step 2: Calculating the current feedback signal
If you compare the shape of the Hall-effect sensor output in Figure 5 from Part 1 and IREF in Figure 4 from this installment, they have the same shape. The only difference is that the Hall-effect sensor output has a DC offset; therefore, it cannot be used directly as the feedback signal. You must remove this DC offset before closing the loop.
 Figure 5 Calculating the current feedback signal. Source: Texas Instruments
Figure 5 Calculating the current feedback signal. Source: Texas Instruments
Also, the normalized Hall-effect sensor output is between (0, +1); after subtracting the DC offset, its magnitude becomes (–0.5, +0.5). To maintain the (–1, +1) normalization range, multiply it by 2, as shown in Equation 7 and Figure 5:
![]()
Step 3: Closing the current loop
Now that you have both the current reference and feedback signal, let’s close the loop. During the positive AC cycle, the control loop has standard negative feedback control. Use Equation 8 to calculate the error going to the control loop:
![]()
During the negative AC cycle, the higher the inductor current, the lower the value of the Hall-effect sensor output; thus, the control loop needs to change from negative feedback to positive feedback. Use Equation 9 to calculate the error going to the control loop:
![]()
Compensator GI processes the error signal, which is usually a PI compensator, as mentioned in Part 1. Sending the output of this PI compensator to the pulse-width modulation (PWM) module will generate the corresponding PWM signals. During a positive cycle, Q2 is the boost switch and controlled by D; Q1 is the synchronous switch and controlled by 1-D. Q4 remains on and Q3 remains off for the whole positive AC half cycle. During a negative cycle, the function of Q1 and Q2 swaps: Q1 becomes the boost switch controlled by D, while Q2 works as a synchronous switch controlled by 1-D. Q3 remains on, and Q4 remains off for the whole negative AC half cycle.
Loop tuning
Tuning a PFC control loop is similar to doing so in an analog PFC design, with the exception that here you need to tune Kp, Ki instead of playing pole-zero. In general, Kp determines how fast the system responds. A higher Kp makes the system more sensitive, but a Kp value that’s too high can cause oscillations.
Ki removes steady-state errors. A higher Ki removes steady-state errors more quickly, but can lead to instability.
It is possible to tune PI manually through trial and error – here is one such tuning procedure:
- Set Kp, Ki to zero.
- Gradually increase Kp until the system’s output starts to oscillate around the setpoint.
- Set Kp to approximately half the value that caused the oscillations.
- Slowly increase Ki to eliminate any remaining steady-state errors, but be careful not to reintroduce oscillations.
- Make small, incremental adjustments to each parameter to achieve the intended system performance.
Knowing the PFC Bode plot makes loop tuning much easier; see reference [1] for a PFC tuning example. One advantage of a digital controller is that it can measure the Bode plot by itself. For example, the Texas Instruments Software Frequency Response Analyzer (SFRA) enables you to quickly measure the frequency response of your digital power converter [2]. The SFRA library contains software functions that inject a frequency into the control loop and measure the response of the system. This process provides the plant frequency response characteristics and the open-loop gain frequency response of the closed-loop system. You can then view the plant and open-loop gain frequency response on a PC-based graphic user interface, as shown in Figure 6. All of the frequency response data is exportable to a CSV file or Microsoft Excel spreadsheet, which you can then use to design the compensation loop.

Figure 6 The Texas Instruments SRFA tool allows for the quick frequency response measurement of your power converter. Source: Texas Instruments
System protection
You can implement system protection through firmware. For example, to implement overvoltage protection (OVP), compare the ADC-measured VOUT with the OVP threshold and shut down PFC if VOUT exceeds this threshold. Since most microcontrollers also have integrated analog comparators with a programmable threshold, using the analog comparator for protection can achieve a faster response than firmware-based protection. Using an analog comparator for protection requires programming its digital-to-analog converter (DAC) value. For an analog comparator with a 12-bit DAC and 3.3V reference, Equation 10 calculates the DAC value as:
![]()
where VTHRESHOLD is the protection threshold, and R1 and R2 are the resistors used in Figure 4 from Part 1.
State machine
From power on to turn-off, PFC operates at different states at different conditions; these states are called the state machine. The PFC state machine transitions from one state to another in response to external inputs or events. Figure 7 shows a simplified PFC state machine.

Figure 7 Simplified PFC state machine that transitions from one state to another in response to external inputs or events. Source: Texas Instruments
Upon power up, PFC enters an idle state, where it measures VAC and checks if there are any faults. If no faults exist and the VAC RMS value is greater than 90V, the relay closes and the PFC starts up, entering a ramp-up state where the PFC gradually ramps up its VOUT by setting the initial voltage-loop setpoint equal to the measured actual VOUT voltage, then gradually increasing the setpoint. Once VOUT reaches its setpoint, the PFC enters a regulate state and will stay there until an abnormal condition occurs, such as overvoltage, overcurrent or overtemperature. If any of these faults occur, the PFC shuts down and enters a fault state. If the VAC RMS value drops below 85V, triggering VAC brownout protection, the PFC also shuts down and enters an idle state to wait until VAC returns to normal.
Interruption
A PFC has many tasks to do during normal operation. Some tasks are urgent and need processing immediately, some tasks are not so urgent and can be processed later, and some tasks need processing regularly. These different task priorities are handled by interruption. Interruptions are events detected by the digital controller that cause a preemption of the normal program flow by pausing the current program and transferring control to a specified user-written firmware routine called the interrupt service routine (ISR). The ISR processes the interrupt event, then resumes normal program flow.
Firmware structure
Figure 8 shows a typical PFC firmware structure. There are three major parts: the background loop, ISR1, and ISR2.

Figure 8 PFC firmware structure with three major parts: the background loop, ISR1, and ISR2.. Source: Texas Instruments
The firmware starts from the function main(). In this function, the controller initializes its peripherals, such as configuring the ADC, PWM, general-purpose input/output, universal asynchronous receiver transmitter (UART), setup protection threshold, configure interrupt, initialize global variable, etc. The controller then enters a background loop that runs infinitely. This background loop contains non-time-critical tasks and tasks that do not need processing regularly.
ISR2 is an interrupt service routine that runs at 10KHz. The triggering of ISR2 suspends the background loop. The CPU jumps to ISR2 and starts executing the code in ISR2. Once ISR2 finishes, the CPU returns to where it was upon suspension and resumes normal program flow.
The tasks in ISR2 that are time-critical or processed regularly include:
- Voltage-loop calculations.
- PFC state machine.
- VAC RMS calculations.
- E-metering.
- UART communication.
- Data logging.
ISR1 is an interrupt service routine running at every PWM cycle: for example, if the PWM frequency is 65KHz, then ISR1 is running at 65KHz. ISR1 has a higher priority than ISR2, which means that if ISR1 triggers when the CPU is in ISR2, ISR2 suspends, and the CPU jumps to ISR1 and starts executing the code in ISR1. Once ISR1 finishes, the CPU goes back to where it was upon suspension and resumes normal program flow.
The tasks in ISR1 are more critical than those in ISR2 and need to be processed more quickly. These include:
- ADC measurement readings.
- Current reference calculations.
- Current-loop calculations.
- Adaptive dead-time adjustments.
- AC voltage-drop detection.
- Firmware-based system protection.
The current loop is an inner loop of average current-mode control. Because its bandwidth must be higher than that of the voltage loop, put the current loop in faster ISR1, and put the voltage loop in slower ISR2.
AC voltage-drop detection
In a server application, when an AC voltage drop occurs, the PFC controller must detect it rapidly and report the voltage drop to the host. Rapid AC voltage-drop detection becomes more important when using a totem-pole bridgeless PFC.
As shown in Figure 9, assuming a positive AC cycle where Q4 is on, the turn-on of synchronous switch Q1 discharges the bulk capacitor, which means that it is no longer possible to guarantee the holdup time.

Figure 9 The bulk capacitor discharging after the AC voltage drops. Source: Texas Instruments
To rapidly detect an AC voltage drop, you can use a firmware phase-locked loop (PLL) [3] to generate an internal sine-wave signal that is in phase with AC input voltage, as shown in Figure 10. Comparing the measured VAC with this PLL sine wave will determine the AC voltage drop, at which point all switches should turn off.

Figure 10 Rapid AC voltage-drop detection by using a firmware PLL to generate an internal sine-wave signal that is in phase with AC input voltage. Source: Texas Instruments
Design your own digital control
Now that you have learned how to use firmware to implement an average current-mode controller, how to tune the control loop, and how to construct the firmware structure, you should be able to design your own digitally controlled PFC. Digital control can do much more. In the third installment of this article series, I will introduce advanced digital control algorithms to reduce THD and improve the power factor.

Bosheng Sun is a system engineer and Senior Member Technical Staff at Texas Instruments, focused on developing digitally controlled high-performance AC/DC solutions for server and industry applications. Bosheng received a Master of Science degree from Cleveland State University, Ohio, USA, in 2003 and a Bachelor of Science degree from Tsinghua University in Beijing in 1995, both in electrical engineering. He has published over 30 papers and holds six U.S. patents.
Related Content
- How to design a digital-controlled PFC, Part 1
- Digital control for power factor correction
- Digital control unveils a new epoch in PFC design
- Power Tips #124: How to improve the power factor of a PFC
- Power Tips #115: How GaN switch integration enables low THD and high efficiency in PFC
- Power Tips #116: How to reduce THD of a PFC
References
- Sun, Bosheng, and Zhong Ye. “UCD3138 PFC Tuning.” Texas Instruments application report, literature No. SLUA709, March 2014.
- Texas Instruments. n.d. SFRA powerSUITE digital power supply software frequency response analyzer tool for C2000
 MCUs. Accessed Dec. 9, 2025.
MCUs. Accessed Dec. 9, 2025. - Bhardwaj, Manish. “Software Phase Locked Loop Design Using C2000 Microcontrollers for Single Phase Grid Connected Inverter.” Texas Instruments application report, literature No. SPRABT3A, July 2017.
The post How to design a digital-controlled PFC, Part 2 appeared first on EDN.
Сторінки


![[link]](https://i.redd.it/v6u4b0ql4kjg1.jpeg){kind=link}