
Feed aggregator
Intel Foundry Advances Chip Power Delivery with Next-Generation Capacitor Technology
Courtesy: Intel
Highlights
- Intel and Intel Foundry researchers demonstrated three promising metal-insulator-metal (MIM) materials delivering intrinsic capacitance density up to 98 femtofarads per square micrometre (fF/μm²), which is significantly higher than the 37 fF/um² intrinsic capacitance density of the material option used in state-of-the-art technology for more efficient chip power delivery.
- Compatible with advanced integrated MIM structures, these technologies deliver leakage well below targets while maintaining stable performance for over 400,000 seconds at elevated temperature, enabling multi-generational improvements without increasing manufacturing complexity.
- These process technology advances aid in the delivery of high performance per watt for chips ranging from data centres to mobile devices, continuing manufacturing efficiency improvements without added fabrication complexity.
Researchers at Intel and Intel Foundry have demonstrated next-generation decoupling capacitor (DCAP) materials that deliver substantial performance improvements for power delivery in advanced computer chips. Presented at the 2025 IEEE International Electron Devices Meeting (IEDM), the breakthrough takes advantage of unique metal-insulator-metal material properties. Ferroelectric hafnium zirconium oxide (HZO) leverages field-dependent dielectric response to achieve 60 to 80 fF/μm², while titanium oxide (TiO) and strontium titanium oxide (STO) reach 80 and 98 fF/μm² through ultra-high dielectric constants — each offering exceptional reliability with minimal voltage dependency.¹ All three materials show negligible capacitance drift over 100,000 seconds, leakage currents much lower than requirements, and 10-year projected breakdown voltages exceeding specifications at 90 degrees Celsius.
These advances have immediate implications for the semiconductor industry and the broader technology sector. Data centres processing artificial intelligence (AI) workloads can maintain high performance per watt longer with higher MIM decap, completing workloads faster while reducing data centre energy consumption and operation costs. Mobile devices benefit from reliable high performance and faster transitions to lower power states, leading to better battery efficiency. High-performance computing (HPC) systems gain processing headroom from a stable supply voltage, enabling maximum frequency for longer durations.
For chip manufacturers, these new capacitor materials offer a path to continue improving power delivery efficiency across multiple technology generations. The materials integrate seamlessly with existing backend manufacturing processes, enabling adoption without major retooling investments. Today’s advanced MIM capacitors often focus on architectural solutions similar to the state-of-the-art Omni MIM used in Intel 18A. Omni MIM has 397 fF/um² capacitance due to its deep-trench and multi-plate structure (see top image). By developing novel oxide materials that integrate seamlessly with these types of structures, the industry can unlock capacitance densities that exceed today’s benchmarks. These technologies help maintain the economic viability of advancing semiconductor manufacturing while meeting the escalating power delivery demands of next-generation processors, accelerators, and systems of chips designs.
The Challenge of Power Delivery in Advanced Chips
As chips pack more transistors into smaller spaces, maintaining stable power delivery grows increasingly difficult. When billions of transistors switch simultaneously, voltage can drop momentarily — called voltage droop — causing processors to slow, make errors, or run at reduced speeds. Decoupling capacitors solve this issue by acting as electrical reservoirs that instantly supply current when needed and absorb excess when demand drops.
Traditional approaches to increasing capacitance involve stacking multiple capacitor layers or etching deeper trenches to create more surface area. However, both significantly increase manufacturing complexity and cost. Material innovations offer an alternative by dramatically increasing the effective dielectric response, which is the material’s ability to store electrical charge. Finding materials with high effective dielectric constants that meet strict reliability requirements for years of operation at elevated temperatures represents a major materials science challenge.
Harnessing Ferroelectric Materials for Voltage-Responsive Capacitance
Ferroelectric hafnium zirconium oxide offers a unique property — the ability to store electrical charge changes with the applied electric field. Unlike conventional dielectrics, where this ability remains constant, ferroelectric materials contain microscopic regions called domains that orient themselves in response to electric fields, enabling different capacitance values at various operating voltages.

Figure 1. Transmission electron microscope image showing the deep-trench capacitor structure used to characterise the MIM stacks.
This type of testing requires careful attention to measurement methods. Under actual decoupling capacitor operation, where a constant bias voltage experiences small disturbances, the material shows remarkably stable capacitance independent of disturbance voltage, hold time, or number of pulses applied. The ferroelectric capacitors deliver 60 to 80 fF/μm² depending on operating voltage. Extensive reliability testing under various voltage levels, elevated temperatures of 90 degrees Celsius, and extended operation exceeding 400,000 seconds demonstrated negligible capacitance drift.
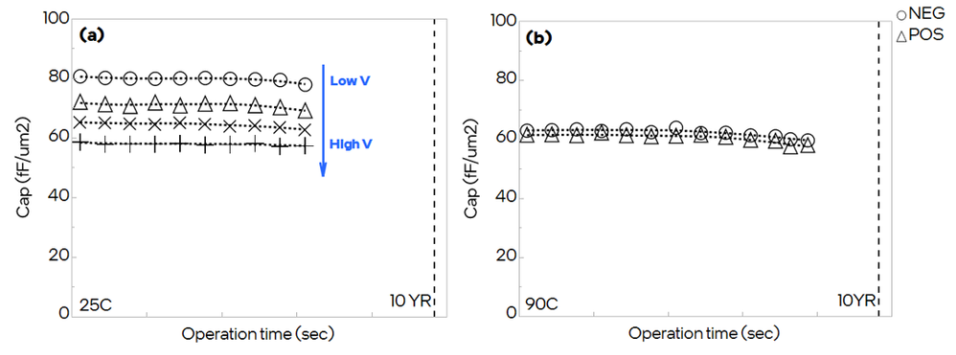
Figure 2. Capacitance measurements showing HZO’s stable, reliable performance under actual decoupling capacitor usage conditions.
Achieving Ultra-High Capacitance with Advanced Dielectric Materials
Titanium oxide and strontium titanium oxide provide even higher capacitance through extremely high dielectric constants with minimal voltage dependency. TiO achieves approximately 80 fF/μm², while STO reaches 98 fF/μm² — the highest demonstrated capacitance density.
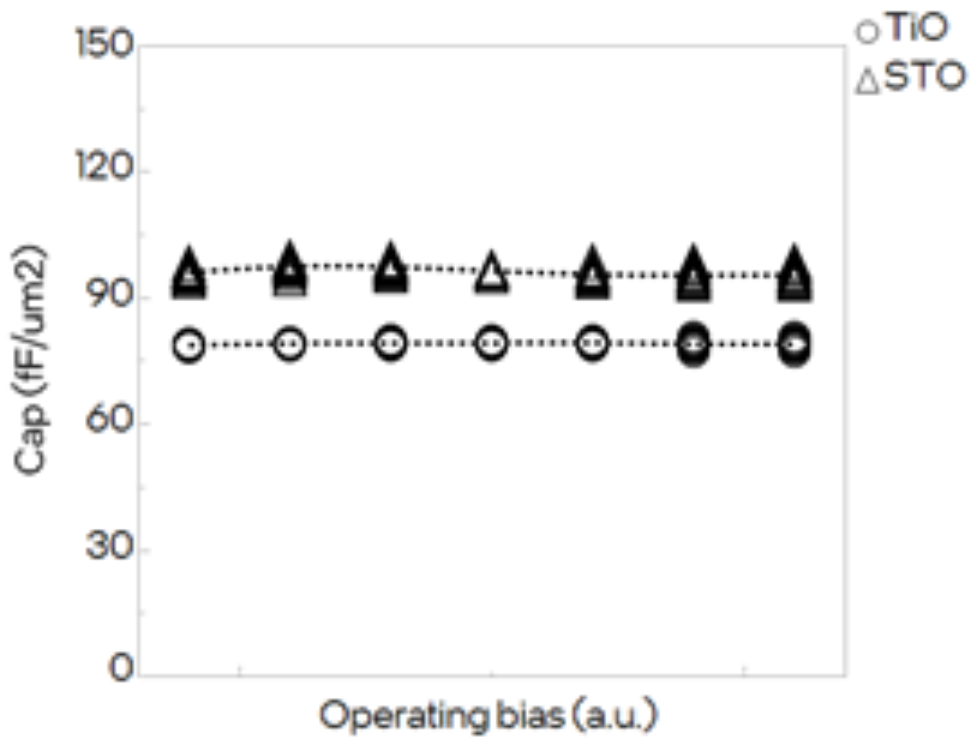
Figure 3. Capacitance versus voltage measurements showing weak voltage dependency across the operating range of interest.
Achieving these performance levels requires precise control over material structure at the atomic scale. The team developed optimised processes, including templating layers that guide crystal growth, controlling film deposition, thermal annealing that promotes desired crystal structure, and interface engineering to minimise defects. X-ray diffraction confirmed the successful production of strong high-dielectric-constant phases in both materials.
For TiO, detailed analysis reveals leakage current follows the Poole-Frenkel mechanism, where electrons trapped at defects gain energy from the electric field and hop between trap sites. This explains why the material withstands high currents without breaking down, with stress-induced leakage behaviour providing self-limiting protection against premature failure.
Exceptional Reliability Enables Multi-Layer Integration
All three materials demonstrate reliability exceeding decoupling capacitor requirements. Leakage current remains below targets even at 90 degrees Celsius. This is achieved through improved dielectric properties rather than making insulators thinner, which would increase leakage.
Time-dependent dielectric breakdown testing stressed devices at higher voltages and elevated temperatures, using statistical models to extrapolate expected lifetime. For HZO, extrapolation predicts operation exceeding high-voltage target spec for 10 years at 90 degrees Celsius with nearly identical breakdown behaviour regardless of voltage polarity. TiO also shows an extrapolated 10-year operating voltage significantly exceeding high-voltage requirements.¹ STO passes reliability targets for lower-voltage applications, though with larger variation due to deposition tooling requiring further optimisation.
The symmetric breakdown behaviour of HZO enables cost-effective multi-layer stacking where multiple capacitor layers connect in series, multiplying total capacitance without requiring complex integration schemes.
Looking Forward: Enabling Next-Generation Computing
This research demonstrates a clear path for continuous decoupling capacitor improvements across multiple semiconductor generations without increasing integration complexity. By improving intrinsic material properties rather than relying on structural innovations like deeper trenches or more layers, these approaches maintain manufacturing feasibility while delivering substantial performance gains.
The three materials provide flexibility for different requirements. HZO offers a practical, near-term option with reliability and straightforward integration. TiO serves as a successor with higher capacitance and exceptional high-voltage capability. STO represents the ultimate capacitance density for applications prioritising maximum capacitance.
Future work will focus on optimising these materials for manufacturing integration, refining deposition processes to improve uniformity, and exploring multi-layer stacking strategies. As computing advances toward AI accelerators, high-performance processors, and energy-efficient data centres, these capacitor technologies will play a vital role in enabling stable power delivery for next-generation semiconductor devices.
The post Intel Foundry Advances Chip Power Delivery with Next-Generation Capacitor Technology appeared first on ELE Times.
Keysight Partners with 3dB Labs to Enable Interoperable Signal Monitoring and Analysis
Keysight Technologies announced the integration of its spectrum analysers and FieldFox handheld analysers with 3dB Labs’ Sceptre, expanding interoperability between signal monitoring hardware and analysis software. The collaboration enables teams to monitor, analyse, and record radio frequency (RF) activity across mixed receiver environments within a unified workflow.
Teams operating in dense and contested RF environments often rely on equipment from multiple vendors while needing a consistent way to observe and interpret spectrum activity. By enabling Keysight instruments to operate directly within the Sceptre software environment, the integration reduces friction between measurement hardware and signal analysis workflows —allowing organisations to maintain multi-vendor receiver architectures while gaining a common platform for signal monitoring and investigation.
Sceptre supports real-time and offline spectrum and temporal analysis and connects receivers deployed on stationary or mobile collection platforms. When paired with Keysight analysers, users can monitor and characterise signals as they appear, capture activity for later playback, and analyse unknown or interfering signals to determine their nature and behaviour. The platform also supports unattended and remote operation, making it suitable for long-duration monitoring, RF surveys, and post-event analysis where access may be constrained.
Together, Keysight and 3dB Labs aim to strengthen the broader signal analysis ecosystem by promoting interoperability between measurement hardware and software-defined receiver platforms. Beyond improving day-to-day operations, the collaboration supports the development of more adaptable signal workflows, encourages integration across traditionally siloed tools, and helps teams build expertise that evolves as signal environments and mission demands change.
Dave Evans, President, 3dB Labs, Inc., said: “We are excited to partner with Keysight and integrate with their FieldFox handheld analysers, bringing Sceptre’s powerful signal detection, identification, and analysis capabilities to the tactical edge. We designed Sceptre for maximum interoperability, enabling teams to move from signal data to decisive action without bottlenecks, and together, we’re delivering an integrated solution that turns advanced signal processing into immediate mission advantage.”
Eric Taylor, Vice President of Aerospace, Defence and Government Solutions, Keysight, said: “Operational environments demand interoperability. By integrating Keysight analysers into multi-vendor ecosystems, teams can spend less time managing tools and more time understanding the spectrum. This integration brings together two leaders in the industry —Keysight in RF measurement and 3dB Labs in signal intelligence — to deliver advanced signal monitoring and analysis capabilities for our customers.”
The post Keysight Partners with 3dB Labs to Enable Interoperable Signal Monitoring and Analysis appeared first on ELE Times.
The story of 10 years, 10 PCBs, and everything I got wrong building a WiFi sub-PPB clock sync device
 | Story time submitted by /u/johny1281 Let me tell you a story about how a simple idea turned into a 10 year obsession. The end result is a tiny (4cm x 4cm) battery-powered node that syncs its clock to other nodes over the air with sub-PPB accuracy. No cables between them. You drop them wherever you want and they self-synchronize. I use it for phase-coherent Wi-Fi measurements across multiple receivers, which lets you do things like angle-of-arrival estimation and indoor localization. But getting here was not pretty. Board 0: The Aliexpress dev kit. I just finished my master's thesis and I've never made a PCB. I grab two ESP32 dev kits, learn how to flash them, learn how to capture Wi-Fi phase data. The data is pure noise. I spend months staring at random numbers before I understand why. Turns out a 10 ppm crystal gives you about 24 full phase rotations between consecutive Wi-Fi frames. Indistinguishable from random. Cool. Board 1: The Chinese flasher board. Before spending real money on a custom PCB I want to make sure I can flash bare ESP32 modules. Got this little Chinese jig, drop the chip in, flash over UART. Works first try. Good confidence boost. Still a garbage clock though. Board 2: First custom PCB ever. This is the big jump. Real money, real components, real chance of screwing up. EasyEDA, auto-router, fingers crossed. I try hand soldering the first batch and destroy every single one. Switched to solder paste and a $30 hot plate. Suddenly everything works beautifully. Same garbage data, but at least I stopped burning money on dead boards. Baby steps. Board 3: The "just share the clock" idea. Upgraded to a 0.5 ppm TCXO and tried to share it between two chips via jumper wires. Seemed so obvious. The parasitic capacitance of even short wires killed the signal dead. Touching a finger near the wire did the same thing. On the plus side, I discovered that the ESP32-C3 has hidden nanosecond RX timestamps buried in the firmware structs. That discovery ended up being the foundation of everything later. Board 4: The SMA cable attempt. Proper 50 ohm coax should fix the clock distribution problem, right? Somehow worse than bare wire. Also picked a clock buffer where the oscillator output was below the CMOS input threshold, so the buffer did literally nothing. Most expensive useless board of the project. Board 5: Two chips, one PCB, as close as physically possible. If cables don't work, just put the oscillator millimeters from both chips. No wires, no connectors, just traces. And it worked! First time I ever saw coherent phase. But the PCB antenna couldn't transmit (2-layer board, matching was completely wrong), and I measured about 1 ppb drift between two chips sitting 5mm apart. Thermal gradients. They're not at exactly the same temperature even when they're neighbors. Board 6: Scale to four chips. Got ambitious. Shared the voltage regulators because I didn't know you can't parallel LDOs. Only 2 out of 4 would boot. External SMA antennas made it the size of a shoebox. Back to the drawing board. Board 7: Remove the ground plane under the clock. Read somewhere online that ground pour causes interference near clock lines. Removed it. Everything got worse. Missing edges on the scope. Noise everywhere. Put it back. Don't believe everything you read. Board 8: Four layers, proper matching. Finally understood why every app note says 4 layers. On a 2-layer board the signal-to-ground distance is too large, coupling is loose, trace dimensions make no sense. On 4 layers everything behaves like the textbook. All 4 chips synced. But all 4 PCB antennas were coupled through the shared ground plane. PCB antennas use the ground as part of the radiating structure. Shared ground = shared antenna. Touching one killed the others. 20 dB down from a reference module. Board 9: Stop sharing clocks entirely. The breakthrough. Give each node its own voltage-controlled oscillator. Measure drift over the air using Wi-Fi timing exchanges. Correct with a DAC on the oscillator's tuning pin. One DAC got me to 10 ppb but each step was too coarse. Added a second DAC in a 1:30 ratio, coarse to get close, fine to hold steady. Sub-PPB. No shared ground, no coupled antennas, no cables. Each node is 4cm x 4cm and battery powered. Board 10: ESP-PPB. A few more boards in between with minor tweaks, but the big addition was the dual-DAC setup. 1 ppb typical in the open. 0.1 ppb in a stable enclosure, which is the measurement floor of the hardware. Oh and one more fun discovery: the radio silently compensates for frequency mismatch between sender and receiver internally. If two boards don't land on the same correction value, your data is garbage and you won't know why. With synced clocks they always agree. With unsynced clocks it's a coin flip. That one cost me months. Everything is open sourceEverything is open source. Firmware, schematics, Gerbers, BOM, 3D model. There's a story.md in the repo with photos of every board and what went wrong each time: https://github.com/jonathanmuller/esp-ppb Ask me anythingWhat was hardest, what was easiest, what I'd redo completely. This has been my side project for a decade and I'm happy to talk about any of it. [link] [comments] |
India to Boost Local Chip-making with a 1 Trillion Rupees Funding
India is expected to unveil a funding of more than a trillion rupees, nearly $10.8 billion, to fuel domestic chip-making. With 10 projects already approved, India aims to become a global manufacturing hub in the near future.
This new set of funds is expected to provide subsidies for chip designing projects, supply chain developments, and manufacturing equipment. Currently, the plan is under evaluation and may see the green light in a couple of months.
With the accelerated demand for chips driven by the rise of AI and electronics, the market is evolving at an exponential rate. Under the current leadership, India aims to position itself at the top to meet global demand.
With companies like Micron, TATA, and Foxconn already building India’s chip ecosystem, the country is expected to be close to industry leaders such as Taiwan and the US by 2032.
The post India to Boost Local Chip-making with a 1 Trillion Rupees Funding appeared first on ELE Times.
OK, this book is awesome!
 | Every connector under the sun is here. Plus it has IC interconnects so this post is technically not breaking the rules :) Thanks Davide for this great resource! [link] [comments] |
Prototype HV DC buck converter running on a PCB I fabricated with a fiber laser
 | This is a quick prototype HV DC buck board I built using the fiber-laser PCB process I posted earlier. Still experimenting with trace limits and thermal performance, but it's working surprisingly well so far. [link] [comments] |
E-ink mp3 player
 | This is V2 of my e-ink DAP project, it has :
V1 horribly failed, here is what changed since then:
The firmware is still in very early stages, I still haven't implemented a ton of features that the hardware is capable of, like DSP, Bluetooth, etc. I also need 3D print the case in resin, so it doesn't look like this, I want to use transparent resin The whole project is open source: GitHub [link] [comments] |
SpiceCrypt: open-source decryption tool for LTspice-encrypted .CIR/.SUB model files
 | submitted by /u/jtsylve [link] [comments] |
USBpwrME
 | Every time i want to do an experiment in the lab and use USB power to my DUT i need to find a cabler with correct connector and thick wires enough for the purpose and then cut it :(:( to be able to connect it to my bench power supply. So finally i decided to solve this reoccurring issue with a universal adaptor that will solve all my challenges and stopping me cutting cable after cable. This led up to designing the small adaptor that fits most power boxes since it has moveable banana binding posts. I have added polarity protection and over voltage protection that can be disabled to make it flexible and pass thru voltages from 3-20V out to the USB-A and USB-C connector. I have also added charging negotiation circuits for both USB-A (up to 10W @ 5V) and USB-C (up to 15W@ 5V). The adaptor can handle up to 6A so it will work for most application!! I have worked a lot with heat managment and tried to keep low resistance in the current paths. When loading max the hottest component reaches around 85 degrees C in room temp [link] [comments] |
Digi-key; A small U.S. town grew a big company. Can it weather the tariff blizzard?
 | submitted by /u/1Davide [link] [comments] |
Weekly discussion, complaint, and rant thread
Open to anything, including discussions, complaints, and rants.
Sub rules do not apply, so don't bother reporting incivility, off-topic, or spam.
Reddit-wide rules do apply.
To see the newest posts, sort the comments by "new" (instead of "best" or "top").
[link] [comments]
Spent hours troubleshooting to find out I got my PFETs backwards qnq
 | I’m attempting to make an LED scoreboard for my cricket team using large 7‑segment LED displays. I want it to be battery powered, so I’m trying to reduce the power needed to run 6+ digits at once by using multiplexing. Each segment is connected to a high‑side switch, and the digits to the low‑side. That way I can turn on each digit by pulling it low, and only the segments held high will activate. The code I’m using runs on an Arduino, which talks to a cheap PCA8695 PWM board. That board connects to a custom MOSFET driver board that handles the high‑ and low‑side switching. Running code that worked fine in my prototype setup just gave me an epileptic strobing effect on all segments, which completely threw me. I spent hours probing with a multimeter, using the oscilloscope at work, and eventually started cutting “non‑essential” components off the board. Instead of getting an inverted 12 V PWM signal like I expected, I was constantly getting a square wave oscillating between 12 V and 11.5 V no matter what I did. I was about to post on r/AskElectronics for help, but I wanted to be 110% sure I wasn’t missing something obvious. So I went to falstad.com and built the circuit in the simulator. Sure enough, it behaved exactly how I expected. Then I noticed a little checkbox for “Swap D/S,” and out of curiosity I clicked it… bingo. For testing, I’m going to desolder the PFETs I’ve got and jankily wire them in upside‑down just to confirm that’s the issue before ordering new ones. Moral of the story: make sure you’re using the right datasheet for your parts, because manufacturers love reusing part numbers even when the pinouts are completely different. (p.s. pls don't be too mean about diagram conventions, signal noise, etc. cos this is a self-taught learning exercise and I'm trying my best) [link] [comments] |
30-minute PCB fabrication with a fiber laser (double-sided boards)
") | I've been experimenting with using a fiber laser to fabricate prototype PCBs. Current workflow: - design PCB - laser isolate traces - drill vias - clean - solder Total time from design to board is about 30 minutes. Trace pitch so far is around ___ mil and I've been able to do reliable double-sided boards. I made a video showing the full process and the relaxation oscillator circuit I designed for it: [link] [comments] |
Exploration Alternatives of Component Marketplaces
 | The goal was to find where to buy electronics that i need(STM32F103C8T6 and STM32F401RET6), but figured it will be cool if i put all that in one post. Maybe someone finds it interesting. [link] [comments] |
IFW Dresden selects Agnitron Agilis 100 MOCVD platform for precursor chemistry and ultra-wide-bandgap materials development
Фінансово-бюджетний звіт за 2025 рік (МОН)
📰 Газета "Київський політехнік" № 9-10 за 2026 (.pdf)
")
Вийшов 9-10 номер газети "Київський політехнік" за 2026 рік
TNO and High Tech Campus Eindhoven begin construction of first 6-inch indium phosphide photonic chip foundry
Balun transformers: Linking balanced to unbalanced

Balun transformers remain indispensable in RF and high-frequency design, serving as the quiet interface between balanced transmission lines and unbalanced circuits. By enabling impedance matching, minimizing signal distortion, and suppressing common-mode noise, they provide the foundation for reliable connectivity in applications ranging from antennas to amplifiers to broadband communication systems.
As wireless technologies push toward higher frequencies and tighter integration, understanding the principles and practical nuances of balun transformers is key to optimizing performance and ensuring design resilience.
The term “balun” itself comes from balanced to unbalanced. While many implementations use transformer coupling, not all baluns are transformer-based—some rely on transmission line techniques. Using “balun transformer” specifies the transformer-type design, distinguishing it from coaxial sleeve or other non-transformer baluns.
Historic note: The iconic TV balun adapter
Before digital tuners and streaming boxes took over, this compact 300 Ω to 75 Ω matching transformer was a fixture in analog television setups. Designed to reconcile the impedance and mode mismatch between twin-lead ribbon antennas and coaxial inputs, it featured screw terminals for the antenna wire and a standard coaxial plug for the TV’s antenna input socket.
Connected at the final stage of the antenna lead and plugged directly into the tuner, it quietly performed its dual role—impedance transformation and balanced-to-unbalanced conversion. This ensured that rooftop signals reached living rooms with minimal distortion. In the analog broadcast era, this unassuming adapter was the last link in the RF chain, faithfully bridging generations of antenna technology.

Figure 1 Screwing the 300 Ω ribbon cable into the balun terminals and plugging its coaxial end into the TV’s antenna input socket completes the balanced-to-unbalanced transition. Source: Author
Video balun transformers: Bridging coax and twisted pair
Video balun transformers—more commonly referred to simply as video baluns in industry parlance—extend the utility of balun technology beyond RF and audio domains into the realm of video signal transmission. These devices convert unbalanced coaxial signals (such as composite video) into balanced signals suitable for twisted-pair cabling, and vice versa.
This conversion not only reduces susceptibility to electromagnetic interference (EMI) but also enables cost-effective long-distance video distribution using standard Cat5/Cat6 cabling. Passive video baluns rely on transformer coupling to maintain signal integrity without external power, while active baluns incorporate amplification and equalization to support higher resolutions or longer cable runs.
In surveillance and broadcast applications, video baluns have become indispensable for bridging legacy coaxial infrastructure with modern structured cabling, ensuring clean signal delivery and simplified installation.

Figure 2 Video baluns connect coaxial BNC interfaces to twisted-pair cabling and deliver HD CCTV signals over long distances with reduced interference. Source: Author
As a quick aside, it’s worth noting that the K and MP ratings of a video balun both denote its supported resolution class. The MP rating specifies the maximum camera resolution in megapixels, while the K rating expresses the same capability in terms of horizontal pixel count.
In practice, both ratings reflect the balun’s bandwidth and signal-handling capacity for HD CCTV. For example, a 4K balun supports roughly 8 megapixels of resolution, since 3840 × 2160 pixels equals about 8.3MP (8.3 million pixels).
Baluns in practice: Theory meets application
Balun transformers are invaluable not only for converting between balanced and unbalanced signals but also for performing impedance transformations with minimal loss. Unlike LC circuits, many balun designs can operate effectively across very wide frequency ranges.
In RF applications, baluns are commonly used to interface antennas with transmitters and receivers, ensuring that as much power as practically possible is delivered. This session blends accessible theory—without heavy mathematics—with a few practical pointers and real-world implementations.
Among the fundamental designs, the balun transformer is the most widely recognized. Using magnetic coupling, it converts between balanced and unbalanced signals while providing excellent isolation and impedance matching. Transmission-line baluns achieve balance through carefully arranged lengths of coaxial or twisted-pair lines, making them well-suited for wideband RF applications.
Hybrid baluns combine transformers and transmission-line techniques, offering flexibility across frequency ranges. Together, these basic types form the foundation for more advanced designs, and understanding their principles helps engineers and experimenters select the right balun for applications ranging from antenna systems to CCTV.
In practice, the terms “balun transformer” and “transformer balun” both refer to the same device: a balun realized through transformer coupling. The difference is mostly in emphasis. Balun transformer highlights the function first—balanced-to-unbalanced conversion—while noting that it’s implemented as a transformer.
Transformer balun highlights the construction first, pointing out that it’s a transformer adapted to serve as a balun. Both usages are common, but in technical writing “balun transformer” is often preferred because it stresses the primary role of the device.
A further distinction often made is between voltage baluns and current baluns. A voltage balun enforces equal voltages on the balanced output terminals, which can work well in many cases but may allow unequal currents if the load is not perfectly symmetrical. In contrast, a current balun enforces equal and opposite currents in the balanced lines, often providing better suppression of common-mode currents on antenna feedlines.
Both approaches have their place: voltage baluns are straightforward and widely used, while current baluns are often preferred in RF antenna systems where minimizing feedline radiation and maintaining balance are critical.
Also essential to audio systems, baluns form the core of passive direct injection (DI) boxes. A passive DI employs a transformer—acting as a voltage balun—to convert an unbalanced, high-impedance instrument signal into a balanced, low-impedance output. This conversion is vital for interfacing high-Z sources such as electric guitars with low-Z mixing console inputs over long cable runs.
By enforcing equal and opposite voltages on the balanced lines, the transformer achieves high common-mode rejection, suppressing noise and ensuring transparent signal transfer. This application demonstrates how the balancing principles fundamental to RF and CCTV extend seamlessly into professional audio, underscoring the cross-domain versatility of balun technology.

Figure 3 A passive DI box handles extreme signal levels without introducing any distortion. Source: Radial Engineering
Seemingly, instead of diving straight into balun transformer–based RF or video projects, makers may find it easier—and just as rewarding—to begin with a closely related audio build: the passive DI box. Ready-to-use direct box transformers are widely available, and their simplicity makes them an ideal starting point for a fun and accessible DIY project.
Notable part numbers include JT-DB-EPC and A187A10C, both excellent examples of components that make this project approachable for beginners. The Hammond 1140-DB-A is another great catch, offering a versatile option for those eager to experiment with high-quality audio designs.

Figure 4 The 1140-DB-A direct box transformer delivers a balanced microphone output from an unbalanced line-level signal, enabling long cable runs with minimal high-frequency loss. Source: Hammond
From first steps to deeper layers
As is often the case, we have only just wetted our feet—there is still a vast ocean of balun transformer theory, design variations, and application nuances left to explore. From specialized wideband implementations to creative DIY builds, each path opens new insights into how these deceptively simple devices shape signal integrity across RF, audio, and video domains.
This overview is meant as a starting point, a foundation for deeper dives into the many layers of balun transformer technology that await.
Your turn: If this sparked your curiosity, take the next step—experiment with a simple antenna balun build, revisit your audio gear with fresh eyes, or explore advanced designs in RF literature. Share your experiences, questions, or even your own schematics, because the best way to deepen understanding is to connect theory with practice.
 T. K. Hareendran is a self-taught electronics enthusiast with a strong passion for innovative circuit design and hands-on technology. He develops both experimental and practical electronic projects, documenting and sharing his work to support fellow tinkerers and learners. Beyond the workbench, he dedicates time to technical writing and hardware evaluations to contribute meaningfully to the maker community.
T. K. Hareendran is a self-taught electronics enthusiast with a strong passion for innovative circuit design and hands-on technology. He develops both experimental and practical electronic projects, documenting and sharing his work to support fellow tinkerers and learners. Beyond the workbench, he dedicates time to technical writing and hardware evaluations to contribute meaningfully to the maker community.
Related Content
- Sevick’s Transmission Line Transformers, Baluns
- Delicate balancing acts ensure balun performance
- Understand baluns for highly integrated RF modules
- Harmonic balance simulation speeds RF mixer design
- Using Baluns and RF Components for Impedance Matching
The post Balun transformers: Linking balanced to unbalanced appeared first on EDN.
Pages


![[link]](https://i.redd.it/6yqak75tz9pg1.png){kind=link}