
Feed aggregator
Guerrilla RF expands focus on tactical radio market
Nexperia brings QDPAK packaging to 1200 V SiC MOSFETs to overcome thermal bottlenecks in high-power designs
ROHM launches new top-side-cooling package for SiC MOSFETs
SemiQ expands high-thermal-performance QSiC Dual3 module range for SSTs and AC–DC converters in AI data-center power systems
Wolfspeed introduces Gen 5 SiC MOSFET technology
Edge AI deployment made easy for system integrators

In 2025, Innodisk launched the “AI beyond the edge” initiative at a forum that also hosted Intel, Nvidia, and Qualcomm, which shared details of their latest developments in edge AI. But what does “AI beyond the edge” really mean?
Don Yu, special assistant to the GM at Innodisk, said that “AI beyond the edge” is about enabling systems that operate autonomously, remain connected, and scale across real-world environments. He also mentioned two complementary domains as part of this initiative.
First, industry AI—built for smart manufacturing, automation, transportation, healthcare, retail, and smart cities—enhances on-site responsiveness through real-time recognition, predictive maintenance, and intelligent workflow optimization.
Second, enterprise AI—designed for data centers, on-premise AI, and advanced models such as large language models (LLMs) and visual language models (VLMs)—supports secure, intelligent decision-making across corporate, financial, medical, and public sectors. “That allows small and mid-size businesses (SMBs) to have their own AI engines locally instead of relying on the cloud,” Yu said.
But despite all the promise, deployment of edge AI has been a challenge so far. So, how are these edge AI initiatives faring so far, EDN asked Yu. And what is Innodisk doing to overcome these challenges in effectively implementing edge AI at scale?
Edge AI deployment challenges
Innodisk chairman Randy Chien acknowledges that the exponential rise of generative AI and LLMs has fundamentally changed the design equation at the edge. More specifically, as AI workloads grow in complexity, companies are facing increasing pressure in system integration, hardware-software coordination, and the ability to scale solutions across diverse deployment environments.
“Anticipating this shift early on, Innodisk has built on its strong hardware foundation by structuring its product portfolio into modular building blocks across memory, storage, camera modules, and a wide range of embedded peripherals,” Yu said. “On this foundation, the company has positioned itself as an AI architect, combining these building blocks to meet diverse industry requirements with tailored edge AI systems.”
So, edge AI developers can implement these solutions as individual modules or as fully integrated systems, depending on their application needs. Take the example of the APEX series of edge AI systems, which brings together key building blocks, including AI accelerators, DRAM modules, flash storage, industrial MIPI and GMSL camera modules, and embedded peripherals for networking and industrial I/O.
“The platform enables flexible system configuration based on specific use cases, while supporting customization to meet diverse deployment requirements,” Yu said.

Figure 1 Individual modules are fully integrated systems tailored according to edge AI application needs. Source: Innodisk
Yu added that Innodisk is heavily investing in firmware and software development to bolster its design ecosystem. Take vision-related AI, for instance, where Innodisk provides fully ported drivers for industrial camera modules, supporting both VLMs and computer-vision applications to streamline deployment and minimize integration friction.
Innodisk also provides specialized software toolkits to accelerate system integration. For example, it has introduced IQ Studio to support the development of Qualcomm-powered edge AI systems. IQ Studio is an open-source developer portal that provides essential board support packages (BSPs), reference code, and benchmarking tools.
How modular solutions aid system integrators
These modular solutions—segmented across five layers of compute, memory, storage, sensing and connectivity, and software—are aimed at addressing design challenges before the last mile of AI deployment in vertical markets. This cohesive system-level approach addresses common development challenges for system integrators and solution providers, enabling them to focus on developing their applications rather than managing integration.

Figure 2 Modular solutions handle integration complexity, which allows system integrators to focus on developing their applications. Source: Innodisk
Moreover, there is a wide range of pre-validated solutions that significantly shorten system integration development cycles. Case in point: AI on Arm series of computer-on-modules (COMs) are designed to be deployment-ready. “They can be directly integrated into customer systems with minimal development effort,” Yu said. “Additionally, they can be paired with Innodisk carrier boards and peripherals to support different system configurations.”

Figure 3 COM modules can be paired with carrier boards and peripherals to support different system configurations. Source: Innodisk
These deployment-ready solutions provide system integrators with practical reference points and inspiration for application design when applied in real-world scenarios. Take the APEX-X200 edge AI platform, for instance, which Innodisk showcased at Nvidia GTC 2026. This on-device inference platform analyzes X-ray and CT images in real time, generating draft medical reports and clinical insights through AI-assisted healthcare workflows.
APEX-X200, powered by an Intel Core Ultra 9 processor, also integrates an Nvidia RTX PRO 6000 Blackwell Server Edition GPU with 24,064 CUDA cores and 752 Tensor cores. Furthermore, it supports up to 96 GB of industrial-grade DDR5 memory and a 1 TB PCIe Gen5 x4 NVMe SSD.
Innodisk has also developed perception systems for heavy machinery and large vehicles in collaboration with its subsidiary Aetina. It integrates the Nvidia Jetson AGX Orin platform with up to eight GMSL2 camera modules alongside capture cards and extenders that support cable lengths up to 30 meters.

Figure 4 The edge AI-based perception system facilitates surround-view stitching, blind-spot detection, and driver-monitoring functions. Source: Innodisk
These perception systems enable surround-view stitching, blind-spot detection, and driver-monitoring functions, supporting real-time environmental awareness and helping identify potential risks such as fatigue or distraction under complex operating conditions. “It’s also an example of a modular architecture that supports future system upgrades without requiring major redesign efforts,” Yu said.
Eyeing U.S. and Europe
Innodisk, headquartered in New Taipei City, Taiwan, has global ambitions with more than 1,000 field-proven edge AI deployments worldwide. In Europe and the Unites States, it’s operating in close collaboration with regional distributors and partners in edge AI segments such as industrial automation, healthcare, aviation, and professional workstations.
Innodisk considers industry events a key tool for bolstering its presence in these crucial markets. It has showcased its edge AI solutions at Nvidia GTC 2026 in the United States, ICE Barcelona in Spain, and Embedded World 2026 and CloudFest 2026 in Germany.
Next, to support global deployment requirements, the company ensures its products comply with regional regulations. Its edge AI solutions meet CE and UKCA requirements for Europe and the U.K. and FCC regulations for the United States.
Also, in Europe, where cybersecurity requirements have become increasingly mandatory, Innodisk attained IEC 62443-4-1 certification in late 2025, embedding security throughout the product development lifecycle rather than treating it as a separate feature. It’s critical because the EU Cyber Resilience Act (CRA) is expected to be fully enforced by 2027.
Related Content
- Top 10 edge AI chips
- Speak Up to Shape Next-Gen Edge AI
- Edge AI powers the next wave of industrial intelligence
- How Advanced Packaging is Unleashing Possibilities for Edge AI
- Edge AI Is Forcing a Rethink of Predictive Maintenance Architecture
The post Edge AI deployment made easy for system integrators appeared first on EDN.
First time soldering!
 | Im so happy that it even works! Took me about an hour. [link] [comments] |
Nexperia and Semikron Danfoss to explore strategic collaboration on SiC power modules for automotive applications
Відновлювана енергетика як одна з підвалин енергетичної стійкості України

Неймовірно важка минула зима показала, наскільки важливими для України є сьогодні питання енергетики. При цьому енергетична безпека під час війни безпосередньо впливає не лише на функціонування економіки, але й стала частиною національної безпеки. В українських медіа навіть можна зустріти тезу про забезпечення енергостійкості як українську національну ідею.
TI Launches a High-Cell-Count Battery Monitor featuring EIS
News highlights:
- The industry’s first 26-cells-in-series channel battery monitor delivers best-in-class sensing accuracy, reducing system costs by supporting more cells per device than competing solutions.
- Integrated smart EIS engine enables early warning of thermal runaway from inside battery cells, helping ensure safety in EVs and ESSs.
- Supports engineers to create safer, higher-performing automotive and industrial applications, the BQ79826Z-Q1 is the latest addition to TI’s portfolio of BMS devices.
Texas Instruments (TI) today introduced the industry’s highest-cell-count battery monitor with an integrated electrochemical impedance spectroscopy (EIS) engine, bringing predictive intelligence, comprehensive data, and real-time diagnostics to battery monitoring in electric vehicles (EV) and Energy Storage System (ESS) applications.
The BQ79826Z-Q1 battery monitor enhances safety and extends battery life by detecting potential failures from within battery cells. The single chip delivers the highest cell count monitoring in its class, tracking up to 44% more channels than previous generations. With this increase in channels, the device significantly decreases the number of components required in a battery pack, reducing system complexity and cost without compromising reliability.
“The electrification of transportation and the rapid expansion of energy storage are redefining what battery performance must deliver, and as a leader in battery management technology, TI is uniquely positioned to meet that challenge,” said Wenjia Liu, vice president and general manager, battery management systems (BMS) at TI.
Delivering safety and performance with EIS technology
Just as an electrocardiogram (EKG) monitors the heart, EIS monitors a battery. It delivers continuous, real-time insight that reveals the battery’s health and warns of issues before they become critical. Integrated EIS technology enables the BQ78926Z-Q1 to detect fault conditions earlier from inside the cells helping maintain safety and notifying passengers of potential vehicle hazards such as thermal runaway.
These same benefits extend to ESSs, where reliable battery monitoring is critical to meeting the growing power demands of artificial intelligence data centers. As effective storage solutions become increasingly vital in the grid-to-gate ecosystem, EIS gives engineers real-time visibility into the state of charge and state of health of each battery cell, regardless of system size.
Maximizing efficiency with industry-leading cell count
The performance of an EV or ESS is fundamentally affected by the quality and efficiency of its batteries. The BQ79826Z-Q1 supports up to 26 cells per device, eight more than any competing solution, setting a new industry standard. Fewer monitoring devices mean a lower bill of materials, simplified architecture, and reduced board space requirements, translating to meaningful cost savings per channel without sacrificing quality or reliability.
When paired with the BQ79881-Q1 pack monitor and optional TI communications bridge, these devices create a powerful chipset that works across different module sizes, battery chemistries, and mechanical designs, giving engineers the flexibility to design once and deploy everywhere. This scalability reduces engineering overhead and accelerates time to market for automotive and energy storage designers.
Calculating charge readings with the best-in-class accuracy
With a voltage accuracy of <2mV across a full temperature range of –40°C to +125°C, higher resolution analog-to-digital converters, and ultra-low noise, the BQ78926Z-Q1 enables more accurate state-of-charge calculations, directly addressing one of the biggest concerns for EV drivers: range anxiety. Utilizing EIS technology, this device enables more accurate temperature and state-of-charge estimation, helping designers achieve longer battery life and faster charging without compromising battery health. With an EIS measurement time that is five times faster than previous solutions, this device delivers the highest functional safety voltage reading per cell. Compliance with Automotive Safety Integrity Level D and International Organization for Standardization 26262 gives designers a smarter, more efficient path to safer, longer-lasting batteries.
The post TI Launches a High-Cell-Count Battery Monitor featuring EIS appeared first on ELE Times.
Derivative-controlled low pass filter, simplified

How to design a simpler filter (or filter-like circuit) with a varying time constant dependent on what kind of waveform is fed to it.
Discussions with some former coworkers have focused on how to design a filter or circuit with filter-like performance that has the characteristic of a slower time constant on on increasing-signal waveforms and a faster time constant on decreasing-signal ones. Such a circuit was proposed in Reference 1, which made use of the Analog Devices AD534 chip.
Wow the engineering world with your unique design: Design Ideas Submission Guide
Along with the “squirming baby” example in Reference 1, another example using such a filter might be a scale at a deli counter, filtering weight as a slice or two is added to the order. When weighing is complete and the slices are removed from the scale, the reading should conversely decrease quickly.
Could there be a different, simplified circuit that might find use in accomplishing the same effect? Thus this Design Idea.
Simplification using an op ampOne way to simplify is to use the same input voltage level as the output, which precludes requiring an input isolation circuit. See Figure 1 for an example.

Figure 1 This simplified derivative-controlled low pass filter has its output at V.
Starting with the circuit in Reference 1 as a foundation, the simplified circuit requires an R1C2 combination to act as the derivative function. The input signal requires a filter, R3C1 as the filter time constant. This derivative signal should be wired to a transistor switch, Q1, a 2N2907A, which discharges that capacitor at a faster rate, R4C1. A non inverting amplifier, ¼ of an LM324N, acts to provide isolation of the derivative input to the transistor switch. This is accomplished by ensuring that the Q1 emitter to base junction is zero, therefore not conducting at steady state.
Figures 2-4 show the actual circuit being tested, and the results.

Figure 2 The circuit in this Design Idea was breadboarded and lab-tested, not just simulated.

Figure 3 In this graph of test results, the red trace is the input, with the output at C1 in blue. Note that the output is at the same level as the input, but the time constants are different.

Figure 4 Conversely, in this graph of test results, the red trace is the output and the blue trace shows the derivative action.
Removing the op amp is possible if the emitter to base junction is biased below the cut-in voltage. Reference 2 has an extensive discussion on the subject, based on the Shockley diode equation. The emitter base junction is the diode in question. There is a point where the forward bias current quite low, assumed to be 1% of the maximum load current. The voltage at that point is considered to be the cut-in voltage; for silicon devices it is assumed to be 0.6V.
For this application, R1 is lowered to 500Ω, which results in a 0.238V difference across the forward-biased Q1 junction, below the cut-in voltage at steady state.

Figure 5 This schematic shows a further simplification of the previous circuit.

Figure 6 In this graph of test results for the further simplified version of the circuit, the red trace is again the input, with the output at C1 in blue.

Figure 7 Conversely, in this graph of test results for the further simplified version of the circuit, the red trace shows the voltage across R1, with the blue trace referencing the C1 voltage. Note the voltage difference in this case.
This circuit will not work for small changes in the input voltage, a topic which is discussed in Reference 1. The values used in these circuits are arbitrary; they can be scaled based on filtering requirements.
References
- Sheingold, Daniel H., Transducer Interfacing Handbook, Analog Devices, Inc., Norwood, MA., 1980.
- Millman, J.; Taub, H., Pulse, Digital, and Switching Waveforms, McGraw-Hill, New York, NY., 1965.
Robert Heider is a retired engineer with over 50 years’ experience with emphasis on the design of advanced process controls and process development.
Related Content
- Simple low-pass filters tunable with a single potentiometer
- Component tolerance sensitivities of single op-amp filter sections
- Filter impedance control
The post Derivative-controlled low pass filter, simplified appeared first on EDN.
CS Applications Catapult to become Semiconductor Catapult
En plain!
 | 200 kva fireworks 😅 [link] [comments] |
DigiKey Expands Asian Electronics Industry with Launch of Vietnam Website
DigiKey, the global distributor of electronic components and automation products, announces the launch of its regional Vietnam website. The new website is tailored to meet the escalating demand for robust supply chain solutions in Vietnam’s expanding electronics and manufacturing sectors.
Vietnam’s exports of computers, electronic products, and components reached $30.72 billion in Q1 of 2026, a 45.5% year-on-year increase, according to Vietnam Customs, underscoring the industry’s role as a leading driver of export growth. Vietnam also remained one of the world’s top mobile phone exporters, ranking third globally, making it an ideal market for DigiKey to support as it grows as a key hub for global electronics manufacturing and supply chain diversification.
“The new DigiKey Vietnam website demonstrates our commitment to supporting our partners and customers in one of Asia’s most dynamic markets,” said Dave Doherty, CEO for DigiKey. “This new platform gives Vietnamese customers access to DigiKey’s global inventory of more than 18 million products, with an emphasis on tailored, localized support and faster, frictionless digital tools. We are thrilled to empower Vietnam’s electronics industry with improved supply chain visibility and custom solutions.”
The post DigiKey Expands Asian Electronics Industry with Launch of Vietnam Website appeared first on ELE Times.
Apple’s question for the developer: Are you up for an AI do-over?

Take two, two years later. That’s the 2026 WWDC in a nutshell, at least for developers. And for consumers? If your Apple Watch is more than a few years old, it’s headed for retirement-and-replacement.
Ironically, albeit not atypically, Apple announced no new hardware at this year’s Worldwide Developers Conference (WWDC) keynote, even though the featured image for the event’s summary press release contained an assortment of it:

And also typically (of late, at least) and as-always disappointingly, the keynote was as-usual pre-recorded.
Which was particularly disappointing in this instance, as the company’s messaging would have benefitted greatly from the presence of live demos, regardless of whether (but especially if) they went off without a hitch. Why? In 2024, Apple made big promises regarding the AI-enhanced version of its Siri virtual assistant and the broader AI-enabled capabilities of its various coming-soon operating systems and application suites.
Two years and a $250 million class action lawsuit settlement later, the company’s trying again, this time in partnership with Google (who held its own developer event just a few weeks ago). I concur with TechCrunch that the demo videos seemed more genuine this time around, with real people interacting with real devices and doing real-life-reminiscent things. Still…pre-recorded.
It’s 2009 all over againBut Apple didn’t lead with AI…sorry, Apple Intelligence…this year. Instead, it focused first on the broader nips and tucks that upcoming (and in the first three cases, already available in developer beta form) 27-series operating systems for computers (just-christened MacOS “Golden Gate”), iOS, iPadOS, watchOS, visionOS and tvOS aspire to deliver above and beyond their generational precursors. All of which takes me back nearly two decades.
At the June 2009 WWDC, Apple unveiled Mac OS 10.6 “Snow Leopard”, which the company proudly trumpeted as having “zero new features” versus its two-years-earlier Mac OS 10.5 “Leopard” predecessor. Instead, Apple focused on, quoting from the Wikipedia entry, “improved performance, greater efficiency and the reduction of its overall memory footprint.” One key means of doing so (quite effectively, in my personal experience along with broader industry reputation) was to strip out legacy PowerPC CPU support. And one year and one O/S generation later, OS X Lion 10.7 also dropped the Rosetta emulation support that had enabled legacy PowerPC-compiled applications to continue to run on top of an Intel x86-centric operating system base.
Fast forward to today and the sense of déjà vu is strong. The last clutch of Intel-based systems (two of which I ironically own, as noted in my last-year’s WWDC coverage) are no longer supported in MacOS 27. And although Rosetta 2 emulation support for x86-compiled code is still baked in, I’d wager that (again like last time) it won’t remain there for long. More generally, all the new operating system versions focused notably on performance, stability and other improvements, such as Liquid Glass U/I tweaks.
The enemy of my enemy…I still struggle a bit to wrap my head around the partnership between Apple and Google on both AI models and cloud services (the latter alongside NVIDIA, interestingly)…but only a bit. After all, as I noted in my recent Google I/O coverage, Google’s on quite a roll right now. Apple had previously worked with OpenAI to add ChatGPT support to Siri, with limited-at-best success as far as I can tell. And OpenAI’s made no secret of its aspirations to deliver Apple-competitive hardware, going so far as to partner with former Apple design chief Sir Jony Ive.

Yes, Google (Android and derivates, including Wear OS, plus ChromeOS and the upcoming “Aluminum”) and Apple (iOS, iPadOS, watchOS, visionOS and tvOS) are market competitors, but so too are Microsoft (Windows) and Apple (MacOS). Microsoft is increasingly becoming a broad AI technology supplier in its own right. And then there’s Meta, still pushing VR, increasingly enthusiastic about smart glasses and rumored to be branching into other hardware. And Amazon, supposedly flirting with smartphones again. And…get my point?
While Apple (along with Apple fanboy sites) goes to great pains to position the Google arrangement as a partnership, I strongly suspect that in reality, Google-developed models were distilled (at most, and maybe not even that) to come up with Apple architecture-optimized versions, leveraging unique acceleration coprocessor capabilities, for example, or using data formats (and sizes of those formats) that inference-execute optimally on Apple Silicon.

Beyond that, along with (I suppose) a dedicated Siri AI app this time around, it all sorta feels like two years ago all over again, this time leveraging a robust trained-model foundation. Which isn’t a bad thing, mind you, quite the contrary. And Apple’s not unrecoverably late, mind you, although if the company had kept waffling for another year or few, I might be saying something different. It’s all just …well…meh.
Obsolescence by design strikes againSwitching to hardware (still mentioned, albeit not newly introduced), and beyond the aforementioned Intel-based computer support demise, the messaging was something of a mixed bag. The company is already beginning to feature-set differentiate between various Apple Silicon system generations, although it hasn’t (yet, at least) started culling any of them from the supported-at-all list. The same goes for iPhones.
Apple has apparently decided that in the midst of a shaky economy, telling folks that they need to go buy new iPhones isn’t a particularly wise move. Similarly, although not exactly so, many (but not all) iPads that run iPadOS 26 are upgradeable to iPad OS 27, too, including I’m happy to say the four fondleslabs in the Dipert household.
And what about smart watches? The story here is unfortunately far more ugly. Apple has apparently decided that in the midst of a shaky economy, it’s still going to be able to (or at least try to) tell lots of folks that they need to go buy new Apple Watches. Including my wife, whose first-generation Watch Ultra has just gotten knifed. I guess I now know what I’ll be buying her for her birthday in a few months…

I’ve only hit here what I thought were the high points; plenty more announcements and tidbits also got covered elsewhere. But what do you think about what I’ve focused on in this piece? As always, let me know your thoughts in the comments!
—Brian Dipert is the associate editor, as well as a contributing editor, at EDN.
Related Content
- The 2024 WWDC: AI stands for Apple Intelligence, you see…
- The 2025 WWDC: From Intel, Apple’s Nearly Free, and the New Interfaces Are…More Shiny?
- Google I/O 2026: Agentic AI gets serious
- Build 2026: Accumulating evidence of Microsoft’s AI independence
The post Apple’s question for the developer: Are you up for an AI do-over? appeared first on EDN.
Navitas introduces isolated through-hole package for 1200–3300V SiC MOSFETs
🎉 Ajax Systems запрошує студентів інженерних спеціальностей відвідати CES

КПІшники, Ajax Systems вдруге організовує студентську поїздку на CES — і розширює програму до 60 учасників! Не проґавте можливість потрапити на одну з найбільших технологічних виставок світу — Consumer Electronics Show (CES) — і побачити, як працює глобальна tech-індустрія зсередини.
WIN’s 0.12µm GaN power process qualified for 40V operation
India’s Defence Boom Risks 10 Years Order Backlog: PwC Study
India’s aerospace and defence (A&D) sector is entering a high-growth phase. Still, execution constraints emerge as the biggest risk to sustaining momentum, according to a new PwC India study titled ‘Accelerating aerospace and defence manufacturing through operational excellence and supply chain resilience’.
The A&D sector is ready to play a catalytic role in India’s economic transformation, helping drive the nearly 16-fold expansion in manufacturing needed to realise the country’s ambition of a $30 trillion economy by 2047. While strong demand, rising exports, and policy support have firmly positioned A&D manufacturing as a key pillar of India’s economic growth, the study highlights that large order backlogs—potentially taking up to a decade to clear—could test the sector’s ability to deliver at scale.
“For India’s aerospace and defence sector, the next phase of growth will be shaped not just by demand, but by the ability to execute with consistency, speed, and precision with scale. Companies that strengthen planning, modernise operations, and build resilient, digitally connected supply chains will be best placed to convert today’s order pipeline into timely, high-quality output at scale,” says Captain Vishal Kanwar, Aerospace Defence and Space Leader, PwC India.
Execution is the real challenge, not the demand
India’s A&D sector is at a turning point. Demand is strong. Exports are rising. But the next phase will be defined by one thing: execution at scale. India now exports defence products to nearly 100 countries. Domestic defence production reached a record ₹1.54 lakh crore in FY25. Yet, large order books are creating pressure on delivery capacity.
For major manufacturers, order backlogs are already significant:
- 1.71x to 6.88x order book-to-revenue multiples
- 2–7 years of execution backlog
- In some segments, up to 5–10 years to clear existing orders
This points to a clear structural challenge. As Dinesh Arora, Partner and Leader, Advisory, PwC India, notes: “The real test for India’s aerospace and defence sector is no longer whether demand exists, but whether the ecosystem can execute with speed, precision, and resilience. As order books expand, companies will need to move beyond incremental capacity addition and fundamentally strengthen planning, shopfloor productivity, supplier coordination, and digital integration. Those that build these capabilities early will be better positioned to convert growth momentum into reliable, globally competitive delivery. Put simply, India has the opportunity. Now it must build the execution engine to match it.”
The blueprint to convert backlog into output
To address the widening gap between order books and execution capacity, the study outlines six priority transformation areas:
- Supply chain efficiency
- Operational excellence
- Planning and governance
- R&D acceleration
- Workforce productivity
- Digital integration (digital thread)
These transformation levers will help the sector move from backlog-led growth to execution-led scale—from stronger operations and shopfloor discipline to digital integration, fostering indigenous vendor ecosystems and supply chain resilience, and smarter use of advanced technologies. These shifts collectively enhance productivity, minimise rework, and provide manufacturers with the necessary tools to execute operations faster, more reliably, and in line with global competitive standards.
The post India’s Defence Boom Risks 10 Years Order Backlog: PwC Study appeared first on ELE Times.
Implantable and Non-Invasive Continuous Health Sensors
Continuous health monitoring is transforming modern medicine. Instead of relying only on occasional hospital visits and laboratory tests, doctors and patients can now access real-time physiological data through advanced sensors. These technologies are broadly divided into two categories: implantable sensors placed inside the body and non-invasive wearable sensors used externally. Together, they are reshaping healthcare by enabling early disease detection, personalized treatment, and remote patient monitoring.
The Rise of Continuous Health Monitoring
Traditional healthcare systems often depend on periodic measurements such as blood pressure checks or glucose testing. However, many medical conditions change continuously throughout the day. Diseases like diabetes, heart disorders, hypertension, and respiratory illnesses require constant observation to prevent complications.
Continuous health sensors solve this problem by collecting data 24/7. Modern devices can monitor heart rate, blood glucose, oxygen saturation, body temperature, movement, respiration, and even biochemical markers in sweat or interstitial fluid. Advances in microelectronics, wireless communication, artificial intelligence (AI), and biosensor engineering have accelerated the development of these smart healthcare systems.
Implantable Health Sensors
Implantable sensors are devices inserted under the skin or within organs to monitor biological signals directly from the body. These sensors provide highly accurate and continuous data because they interact closely with tissues and body fluids.
Examples of Implantable Sensors
One of the most successful implantable technologies is the continuous glucose monitor (CGM) used for diabetes management. Devices such as implantable glucose sensors can remain under the skin for months and transmit blood sugar readings to smartphones in real time. Recent FDA-cleared systems can operate for up to one year before replacement.
Another major application is implantable cardiac monitors. These miniature devices continuously track heart rhythms and help physicians detect arrhythmias or irregular heartbeats. Modern systems are tiny, minimally invasive, and capable of remote data transmission to healthcare providers.
Researchers are also developing advanced implantable biosensors capable of measuring oxygen levels, tissue health, metabolic activity, and even neurological signals. Some experimental devices are battery-free and powered wirelessly through magnetic or inductive coupling technologies.
Illustration: Implantable Biosensor Technology
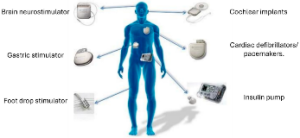
Implantable sensors offer several important advantages:
- High measurement accuracy due to direct contact with internal tissues
- Continuous long-term monitoring without user intervention
- Early detection of medical emergencies
- Improved disease management and personalized treatment
- Reduced hospital visits through remote monitoring
These devices are especially useful for chronic diseases that require precise data over long periods.
Challenges and RisksDespite their advantages, implantable devices face technical and ethical challenges. Biocompatibility is critical because the body may react negatively to foreign materials. Power supply and wireless communication remain engineering challenges, particularly for miniaturized implants.
Cybersecurity is another concern. Since implantable devices transmit sensitive health data wirelessly, they may become targets for hacking or unauthorized access. Researchers are therefore developing secure communication protocols for medical implants.
Non-Invasive Wearable SensorsNon-invasive sensors are external devices worn on the body. These include smartwatches, fitness bands, adhesive patches, smart clothing, and portable biosensors. Wearables have become extremely popular because they are convenient, affordable, and easy to use.
Modern wearable devices can measure heart rate, electrocardiograms (ECG), sleep patterns, stress levels, physical activity, oxygen saturation, and body temperature. Some advanced systems also estimate blood pressure and glucose levels using optical or electrochemical techniques.
Illustration: Wearable Health Monitoring DevicesWearable Biosensors in Healthcare
Wearable biosensors are increasingly used in hospitals and home healthcare environments. Chest-worn biosensors can continuously monitor ECG, respiration, temperature, and motion while transmitting data to cloud platforms for medical analysis.
Smartwatches now include AI-driven health features capable of detecting irregular heart rhythms and providing health alerts. During the COVID-19 pandemic, wearable monitoring gained importance because patients could be observed remotely without frequent hospital visits.
Flexible and epidermal sensors are another exciting innovation. These ultra-thin electronic patches attach directly to the skin and can monitor sweat composition, hydration, muscle activity, and biochemical signals with minimal discomfort.
Role of Artificial Intelligence and Big Data
Artificial intelligence is becoming a central component of continuous health monitoring systems. AI algorithms analyze sensor data to identify abnormalities, predict disease risks, and provide personalized recommendations.
For example, AI can detect early signs of atrial fibrillation from smartwatch ECG data or predict dangerous glucose fluctuations before symptoms occur. Cloud computing and Internet of Things (IoT) technologies allow healthcare providers to monitor thousands of patients remotely and respond quickly during emergencies.
The integration of AI with biosensors is expected to create predictive healthcare systems where diseases are identified before they become severe.
Future Research and Innovations
The future of health sensors lies in miniaturization, flexibility, and multi-parameter monitoring. Researchers are developing implantable biosensors that can simultaneously measure multiple biochemical markers using advanced nanotechnology and microelectromechanical systems (MEMS).
Future devices may include:
- Battery-free implantable sensors
- Smart tattoos for biochemical monitoring
- Flexible electronic skin
- AI-powered diagnostic wearables
- Wireless neural implants
- Real-time personalized drug delivery systems
As technology advances, healthcare may shift from reactive treatment to proactive prevention.
Conclusion
Implantable and non-invasive continuous health sensors represent one of the most important technological revolutions in modern medicine. Implantable devices provide accurate internal monitoring, while wearable sensors offer convenient and affordable health tracking for everyday use. Together with AI, wireless communication, and biosensor research, these technologies are enabling a future of personalized, preventive, and data-driven healthcare.
Although challenges related to safety, cybersecurity, cost, and regulatory approval remain, continuous health sensors are expected to play a major role in improving global healthcare systems and patient quality of life in the coming decades.
The post Implantable and Non-Invasive Continuous Health Sensors appeared first on ELE Times.
Pages


![[link]](https://i.redd.it/zgtyp5tu586h1.jpeg){kind=link}